Gazette Linux n°073 — Décembre 2001
Prénom Nom du relecteur
Relecture de la version française<adresse_électronique CHEZ fournisseur POINT code_pays>Copyright © 2001 Wolfgang Mauerer
Copyright © 2016 Sébastien Marbrier
Copyright © Année de relecture Prénom Nom du relecteur
Article paru dans le n°073 de la Gazette Linux de décembre 2001.
Cet article est publié selon les termes de la Open Publication License. La Linux Gazette n'est ni produite, ni sponsorisée, ni avalisée par notre hébergeur principal, SSC, Inc.
Table des matières
L'erreur est humaine. Les Programmeurs sont humains. L'incroyable complexité et l'inébranlable logique inhérentes à ces petits mots pourraient bien causer des années de discussions parmi les philosophes mais tenant là sans aucun doute une vérité intemporelle, cela nous ramène encore à un sujet bien terre-à-terre : tous les programmes écrits par des humains sont remplis d'erreurs. Bien que la croyance que la programmation ne soit rien de plus qu'une discipline mécanique et bête qui pourrait être accomplie sans faire la moindre erreur si l'on prenait suffisamment de précautions et de planification soit encore vivace, une autre approche plus pragmatique peut paraître au premier abord démoralisante pour les programmeurs : rien ne marche, les programmes sont truffés d'erreurs, les spécifications sont fausses et l'implémentation donne le contraire de ce qui est attendu. Mais ce n'est pas contre les programmeurs, bien au contraire, la programmation est une tâche très compliquée et incertaine, par conséquent les erreurs sont inévitables, y compris pour les meilleurs programmeurs — seules les tâches faciles peuvent être accomplies sans erreur. Les erreurs ont leur importance ou exactement : la façon dont on trouve et que l'on corrige ces erreurs dans le cycle de vie d'un logiciel est une tâche dont l'importance ne sera jamais assez soulignée. La découverte d'erreurs n'est simplement qu'une partie inévitable du développement mais surtout une composante essentielle de la vie de tout système logiciel.
Il est donc évident que les bogues doivent être trouvées et des outils adaptés sont nécessaires pour assister le développeur dans cette tâche difficile. La plupart d'entre vous doivent savoir qu'il existe un très bon débogueur libre issu du projet GNU (qui d'autre?). Les membres du projet GNU s'occupent également du plus important compilateur sous Linux, le compilateur c gnu. Ces deux programmes forment une équipe fabuleuse et capitale pour éliminer les horribles bogues dans vos programmes. Ceux d'entre vous qui ont déjà utilisé le débogueur connaissent son interface spartiate : elle n'est pas mauvaise mais elle n'est pas non plus idéale. Même pour l'amateur de la ligne de commande et des utilitaires en mode texte (l'auteur en est un), les interactions avec le débogueur ne sont pas toujours une partie de plaisir et peuvent mettre les nerfs à rude épreuve, en particulier lorsqu'il faut corriger de plus grands systèmes avec des structures de données complexes. L'interface textuelle est peut-être adaptée pour le déplacement pas-à-pas dans le programme, vérifier des valeurs simples ou tester certaines conditions mais ce n'est certainement pas le choix optimal pour un débogage moderne, efficace et facile de structures fortement liées les unes aux autres. D'autres interfaces (comme le mode gud) d'emacs ou la nouvelle interface tui de gdb) apportent un peu plus de confort mais ce n'est toujours pas l'idéal.
Nous avons donc besoin d'une interface graphique et une nouvelle fois, le projet GNU propose une très bonne solution : DDD, le débogueur d'affichage de données. DDD est une interface graphique écrite par et (et avec l'aide de nombreux programmeurs de la communauté du logiciel libre) et a intégré le programme GNU voilà quelques temps (alors qu'il était déjà disponible sous licence GPL). Si le débogage n'était pas si difficile par moments, on serait presque tenté de dire que le débogage avec ddd serait du pur plaisir.
Qu'apporte ddd par rapport l'interface native de gdb ou celle des frontaux tels que le mode gud d'emacs? Le principal n'est pas simplement les fonctions de débogage normales de DDD (c-à-d avance ligne-à-ligne, positionner des points d'arrêt et de surveillance, changer la valeur des variables du programme), qui sont supportées par ddd (d'une façon très pratique et bien plus aisée par rapport à l'interface traditionnelle de gdb), mais ddd peut aussi afficher graphiquement des structures de données. Qu'est-ce que cela signifie? Prenons une liste chaînée en C que nous utiliserons dans les exemples ultérieurs. La structure de données est composée de plusieurs champs de données avec un ou plusieurs champs pointant vers d'autres structures du même type, formant ensemble un réseau interconnecté. Ce réseau est constitué par les valeurs des variables pointeurs. Il pourrait être reconstitué par ses valeurs hexadécimale, donnant l'emplacement en mémoire des éléments précédents ou suivants, mais c'est une tâche qui n'est ni aisée ni pratique. Il est très difficile de donner un aperçu concis de la situation de cette façon; et même si le programmeur réussit ce travail laborieux, il y a un inconvénient majeur : comme l'emplacement en mémoire change à chaque exécution (ou avec un jeu de données d'entrée différent), ce travail devient rapidement inutile. DDD permet de surmonter cette limitation en créant automatiquement des diagrammes à partir du contenu de la mémoire, permettant de visualiser agréablement et simplement des structures complexes.
Mais la capacité de dessiner des structures de programme n'est pas la seule amélioration apportée par ddd par rapport aux méthodes classiques de débogage interactif:
La capacité de basculer automatiquement entre plusieurs fichiers source.
Une vue commode de l'ensemble du texte du programme (pas seulement quelques lignes autour de l'instruction courante).
Plusieurs débogueurs sont supportés. Cela signifie que ddd peut non seulement fonctionner avec gdb en tant que processus de débogage arrière, mais il peut également utiliser des débogueurs pour les langages de scripts Python et Perl, le débogueur java de Sun ou bien dbx et ladebug (sur des systèmes autres que GNU/Linux).
De nombreux langages sont supportés. Ce n'est pas seulement en raison de sa faculté à accepter différents débogueurs mais c'est aussi un bénéfice venant du support par gdb de différents langages source (C, C++, Objective C, Fortran, Java, ...)
L'interface est commune pour tous les langages supportés par les débogueurs sous-jacents.
Allons voir comment tout cela fonctionne en pratique en déboguant un programme d'exemple simple.
Les programmes binaires ne comportent normalement pas d'information sur le fichier source; ils exécutent uniquement leur code en terme d'instructions machines. Par conséquent, il est nécessaire d'inclure ce que l'on appelle des symboles de débogage dans le code objet avant de pouvoir utiliser les fonctions avancées d'un débogueur (à défaut, il est possible d'avancer dans le programme instruction par instruction, mais sans relation directe avec le code source, cela n'est pas très utile). Il existe quelques formats de débogage dans le monde Unix mais nous n'irons pas plus loin car c'est un sujet qui intéresse surtout les programmeurs de compilateurs. Nous nous concentrerons sur la plate-forme GNU/Linux en utilisant les compilateur C GNU avec les réglages par défaut.
L'option standard pour inclure les informations de débogage dans un programme est -g lorsque l'on appelle gcc:
[wolfgang@jupiter wolfgang]$ gcc -g fac.c -o fac
Un fichier binaire fac sera crée, il aura une plus grande taille que l’exécutable normal.
Ce n'est évidemment pas une véritable surprise: l’ajout de données supplémentaires (telles que l’association entres les blocs d'instructions machine et les numéros de ligne dans le code source, etc) sont maintenant stockées dans le code,
la taille doit augmenter.
Il est important de noter que gcc propose une fonctionnalité assez rare parmi les autres compilateurs comparables : les informations de débogage peuvent être générées même avec l'optimisation activée par exemple gcc -g -O2 fac.c fac
fonctionnera, elle générera une fichier binaire qui sera optimisé et qui contiendra les informations de débogage.
Bien que cela puisse être assez pratique dans certains cas, il y a quelques chausses-trappes bien cachées derrière cette approche (comme l'optimisation de plusieurs lignes de code), nous n'étudierons donc pas ces combinaisons ici.
Le fichier source de fac.c contient:
#include <stdio.h>
int main() {
int indice;
int fac;
for (indice = 1; indice < 10; indice++) {
fac = factorielle(indice);
printf("indice: %u, fac: %u\n", indice, fac);
}
return 0;
}
int factorielle(int num) {
if (num = 0) {
return 1;
}
else {
return num * factorielle(num - 1);
}
}
Comme vous pouvez le voir, le programme ne réalise que des calculs très simples : on boucle dans un intervalle de valeurs entières comprises entre 1 et 9 et on appelle une fonction pour calculer la factorielle du nombre à chaque itération. Il est tout à fait évident que cela pourrait être réalisé de manière beaucoup plus efficace, mais c'est un bon exemple pour les techniques de débogages classiques. À propos : il ne fonctionnera pas correctement, car il contient une erreur. Vous pouvez vérifier en exécutant ce programme dans un interpréteur de commandes normal, sans débogueur (les binaires avec les symboles de débogage fonctionnent comme les programmes normaux, ils sont juste un peu plus lents): vous n'obtiendrez qu'un extrait de la mémoire suite à une erreur de segmentation. Faisons tourner le programme dans le débogueur pour découvrir ce qui ne va pas !
ddd s'exécute avec la commande
[wolfgang@jupiter Wolfgang]$ ddd &dans votre invite de commande; le nom du programme à déboguer peut être passé en tant que paramètre optionnel. Si ddd n'est pas installé sur votre système, cela peut se faire très certainement avec votre gestionnaire de paquet favori (tel que apt-get, rpm etc.), les binaires de ddd étant fournis dans toutes les distributions principales. Dans le cas où il n'y aurait pas de paquet binaire pour votre système (ou si vous voulez compiler ddd de zéro pour quelque raison que ce soit), récupérez les sources depuis ftp.gnu.org (ou de préférence d'un de ses miroirs) et suivez les instructions du fichier INSTALL fourni.
Si vous ne passez pas le nom du fichier par la ligne de commande, vous pouvez le sélectionner via une boite de dialogue accessible depuis l'entrée → du menu Programme. Ddd charge ensuite ce programme, analyse les symboles de débogage (ou, pour être exact: laisse le débogueur d'arrière-plan analyser les symboles) et charge ensuite le fichier source principal. Vous devriez voir une fenêtre similaire à la figure 1.
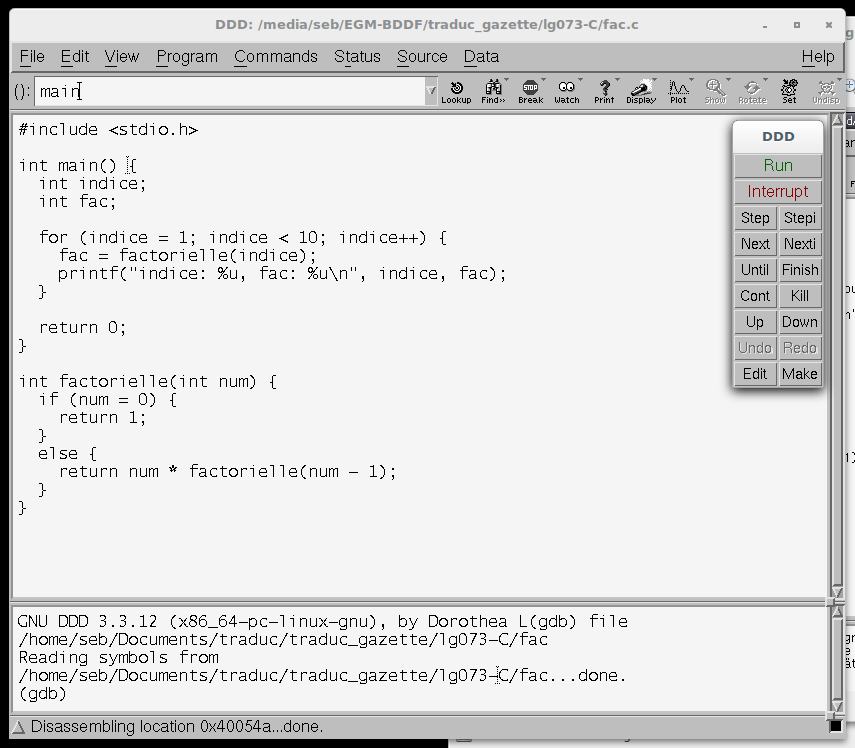
Figure 1: la fenêtre principale de ddd
La sous-fenêtre "Command tool" est très importante pour nos travaux futurs. Par défaut, elle se trouve dans la partie droite de la fenêtre principale, elle propose plusieurs boutons pour réaliser différentes actions sur notre code (dans le cas où nous fermerions la fenêtre accidentellement, on peut la rouvrir soit avec F8 ou avec l'item → ).
Déroulons le programme ligne par ligne et observons précisément ce qu'il se passe durant son exécution.
Pour cela, nous devons démarrer le programme et définir un point d'arrêt pour empêcher que le programme ne s’exécute entièrement avoir d'avoir la possibilité de l'interrompre.
Un point d'arrêt suspend l’exécution du programme à une ligne de source donnée, donnant l'opportunité d’interagir avec le débogueur et d’effectuer des actions de débogage.
Pointez votre souris sur le côté gauche de la fenêtre source sur la ligne int indice;, faites un clic droit et sélectionnez "Set Breakpoint" dans le menu surgissant.
Un signe stop rouge apparaîtra sur la ligne correspondante, indiquant que l’exécution du programme sera interrompue dès qu'elle atteindra ce point.
Nous pouvons à présent dérouler la chose: sélectionner "run" depuis l'outil commande, qui indiquera au débogueur de démarrer le programme. Le programme ne fonctionne pas très longtemps, car notre point d'arrêt se trouve au tout début du fichier; nous sommes à présent dans le mode interactif du débogueur. La flèche verte à gauche des lignes de source nous montre la prochaine ligne qui sera exécutée dans le fichier source.
Il y a deux façons de parcourir un code source: alors que "next" avance ligne à ligne, mais ne rentre pas dans les appels de fonction (et ne donne que le résultat de l'appel), "step" entrera dans le code de la sous-routine lorsqu'elle sera appelée. Comme nous voulons ce qu'il ne va pas dans notre programme (vu que l'erreur est très courante, les programmeurs expérimentés l'ont certainement déjà trouvée), nous décidons parcourir le programme avec "step". Appuyez sur le bouton, et vous retrouverez le pointeur vert au tout début de la sous-routine factorielle. C'est ce que nous attention, vous pouvez alors appuyer sur "step" une nouvelle fois, la flèche verte ira directement dans le branchement du else de notre test conditionnel. Là encore, tout va bien. Qu'attendons-nous à présent? Sachant que num vaut 1 quand nous à l'entrée de la sous-routine, elle devrait être 0 quand nous entrerons récursivement de nouveau dans la sous-routine, provoquant un retour immédiat de la valeur 1, ce qui causera en retour 1*1=1 depuis le premier appel de factorielle, nous renvoyant dans le programme principal. Vérifions que c'est bien ce qu'il passe réellement en appuyant sur "step" une fois de plus: le pointeur vert se place de nouveau au début de la fonction, mais entre de nouveau dans la branche else à l'itération suivante! Il est clair que quelque chose ne va pas: nous devons vérifier la valeur de num.
Il existe différentes façons de visualiser le contenu de variables simples (c-à-d les variables de type de base tels que int, long, float etc.). La plus répandue est de maintenir le pointeur de souris au-dessus de la variable dans la fenêtre source, en attendant qu'une infobulle apparaisse à l'écran avec son contenu. Un moyen alternatif consiste à appuyer sur le bouton droit de la souris juste au-dessus de l'identifiant et de sélectionner Print num dans le menu surgissant ou de marquer l'identifiant et de sélectionner l'entrée de menu . Avec les deux dernières méthodes, la valeur est affichée dans de fenêtre de sortie gdb dans la partie basse de la fenêtre principale.
Quelque soit la méthode choisie, nous obtenons 0 comme valeur de num. Pourquoi avons-nous pris la seconde branche alors que la valeur est 0? En faisant un "step" supplémentaire; on confirme une hypothèse sur l'erreur: si l'on regarde la valeur de num au tout début de la fonction, nous constatons qu'elle vaut -1, mais au "step" suivant (encore une fois la deuxième branche du test conditionnel if), c'est de nouveau 0 : l'erreur provient d'un = oublié dans la clause du if, ce qui provoque une affectation au lieu d'une comparaison! Bien que ce soit une erreur très répandue dans les programmes écrits en C, elle peut provoquer d'importants retards dans le développement du programme si elle est suffisamment bien cachée. Puisque que nous n'obtiendrons aucun résultat significatif de ce programme défectueux, nous pouvons le terminer avec le bouton "kill" — dans la fenêtre d’exécution.
Corrigeons l'erreur en remplaçant "=" par "==", recompilons le programme (n'oubliez pas d'inclure à nouveau les symboles de débogage! ) et de le recharger dans ddd grâce au menu . Comme vous pouvez le constater, notre point d'arrêt est conservé, nous pouvons donc redémarrer le programme depuis le tout début. Si nous appliquons "step" dans l'appel à factorielle, tout fonctionne correctement. La fonction factorielle se termine, le pointeur de ligne source est à présent sur la ligne printf(...). Nous devons être prudent : si nous sélectionnons "step" encore une fois, ddd tentera de rentrer dans l'appel à printf, ce qui n'est pas possible, car la fonction provient de la librairie C standard qui n'est normalement pas compilée avec les symboles de débogages (bien que cela soit néanmoins possible). Dans ce cas, nous allons donc préférer "next". "Step" provoquerait un message d'erreur à propos de plusieurs fichiers source manquants; il faudrait un certain nombre de clics sur "next" pour remettre le pointeur vert sur notre code source.
Dans notre premier exemple simple, ddd ressemble aux autres interfaces telles que le mode gud d'emacs (bien qu'avec un meilleur confort).
Mais il y a ici une fonctionnalité unique et merveilleuse de ddd: la capacité d'afficher graphiquement des structures imbriquées.
Afin de démontrer les fonctionnalités correspondantes, nous avons besoin d'un nouveau programme d'exemple.
list.c:
#include <stdio.h>
int main() {
typedef struct personne_struct {
/* Elements de données */
char* nom;
int age;
/* Elements de liaison */
struct personne_struct *suiv;
struct personne_struct *prec;
} personne_t;
personne_t *debut;
personne_t *pers;
personne_t *temp;
char *noms[] = {"Linus Torvalds", "Alan Cox", "Rik van Riel"};
int ages[] = {30, 31, 32};
int compteur; /* Compteur temporaire */
debut = (personne_t*)malloc(sizeof(personne_t));
debut->nom = noms[0];
debut->age = ages[0];
debut->prec = NULL;
debut->suiv = NULL;
pers = debut;
for (compteur=1; compteur < 3; compteur++) {
temp = (personne_t*)malloc(sizeof(personne_t));
temp->nom = noms[compteur];
temp->age = ages[compteur];
pers->suiv = temp;
temp->prec = pers;
pers = temp;
}
temp->suiv = NULL;
printf("Structure de données crée\n");
return 0;
}
Il se peut que vous connaissiez les noms utilisés dans cet exemple mais ils ne sont pas importants. Les âges sont pris au hasard!
Le code définit une double liste chaînée d'éléments personne qui regroupe deux informations personnelles (nom et age) ainsi que deux pointeurs (vers l'élément suivant et vers l'élément précédent dans la liste). S'agissant d'une des structures les plus importantes en C, tout programmeur doit avoir rencontré à plusieurs reprises ce genre de choses, normalement dans un ensemble plus complexe. Comme précédemment, notre programme ne réalise pas une tâche trop complexe: il se contente de construire la structure de données en mémoire et se termine; mais c'est suffisant pour notre objectif. Comme à chaque fois, le programme doit être compilé avec les symboles de débogage et chargé dans ddd.
Cette fois, nous avons placé notre premier point d'arrêt à la ligne 28 (le début de la boucle for) et démarré notre programme. Placez le pointeur de souris au-dessus de l'identifiant debut: ddd montrera dans l'infobulle qui apparaît après un petit moment que c'est une instance de struct personne_t dans un emplacement mémoire donné en notation hexadécimale. Un candidat parfait pour une visualisation graphique !
Faites surgir le menu contextuel en pressant le bouton droit de la souris sur l'identifiant debut et sélectionnez "Display *debut" — l'étoile est nécessaire pour que ddd déréférence automatiquement le pointeur et montre le contenu de la structure. Une nouvelle section dans la partie supérieure de la fenêtre de ddd apparaîtra, elle contiendra une représentation du contenu de debut: nom et age sont initialisés avec les valeurs assignées quelques lignes avant, et suiv, prev contiennent les pointeurs NULL comme attendu. La figure 2 montre le cadre que vous devriez voir sur votre écran (la valeur hexadécimale du pointeur de caractère peut changer sur votre système).
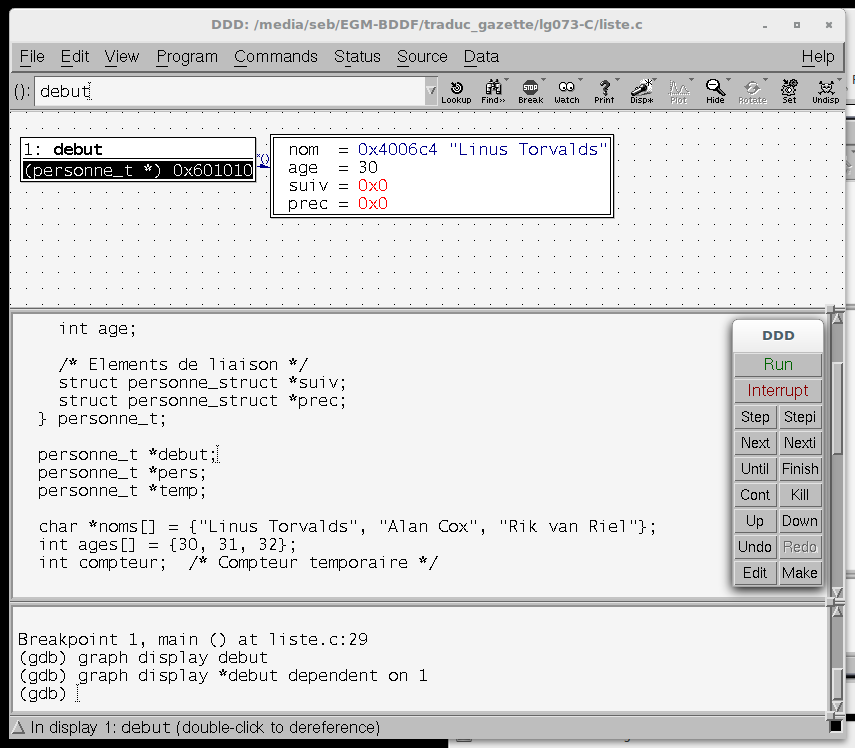
Figure 2: Visualisation d'une structure de données
N'est-ce pas une fonctionnalité particulièrement intéressante ? Avançons encore un peu dans notre programme pour découvrir comment notre structure de données est construite en mémoire.
Utilisons le bouton "suivant" pour traverser le corps de la boucle for
jusqu'à ce que la ligne 34 (pers->suiv = temp) soit atteinte: la seconde structure de données personne est construite et reliée à la première par prec.
Quand vous visualiserez ensuite le graphique, vous pouvez voir que le champ suiv de la première personne contient maintenant une valeur différente de 0, ce qui signifie qu'elle pointe vers une autre structure, cerise sur le gâteau: si vous double-cliquez
sur cette valeur, une nouvelle boite avec la structure de la deuxième personne s'ouvre, et le pointeur de personne 1 vers personne 2 s'affiche automatiquement sous la forme d'une flèche entre les boites.
Nous allons créer différemment la structure de données pour la troisième personne, car ce n'est pas pratique de parcourir toutes les lignes de code simplement pour voir le résultat. Plaçons un autre point d'arrêt à la ligne 39 qui contient l'instruction printf(...). L'appui sur "cont" relance le déroulement du programme jusqu'au point d'arrêt suivant (celui que nous venons de créer).
Nous pouvons afficher la structure de données de la troisième personne comme nous l'avons fait jusqu'à présent. Mais cette fois, nous ne voulons pas seulement visualiser les pointeur de la personne n à la personne n+1, mais également les pointeurs arrière! Double-cliquez, par exemple sur le champ prec du deuxième graphique: une nouvelle boîte surgit, dupliquant l'affichage de la boîte de la première personne ! La même chose se produit pour le pointeur prec de la troisième personne. Il est évident que ce n'est pas ce que nous voulons, car la même structure ne devrait pas être affichée deux fois. Nous devons indiquer à ddd de prendre en charge ce cas.
Pour y parvenir, ddd se sert d'une fonctionnalité appelée détection d'alias, elle peut être activée avec l'entrée . L'affichage devrait à présent être comme dans la figure 3.

Figure 3: Une liste chaînée de personnes
Tous les pointeurs sont affichés correctement, ce qui nous donne une assez bonne image de la structure de données en mémoire. Malheureusement, la détection d'alias a l'inconvénient de ralentir ddd, et ce particulièrement avec les structures fortement liées, en raison de la comparaison entre de nombreux emplacements mémoire qui doit être faite à chaque instruction du programme pour déterminer quelles sont les structures dans l'affichage qui représentent le même espace mémoire, en compactant le graphique. De plus, la détection d'alias n'est possible qu'avec les langages source qui supportent le débogueur arrière pour fournir les adresses d'objets arbitraires, ce qui limite actuellement nos possibilités à C, C++ et Java.
Un exemple plus complexe
Considérons un exemple légèrement plus complexe (au moins avec les relations vers la structure de données créée) afin de démontrer les capacités d'affichage de ddd.
Nous utiliserons le code source ci-dessous (arith.c):
#include <stdio.h>
/* Cree une structure d'arbre binaire, representant une expression arithmetique */
enum operateur { plus, moins, mul, div };
typedef struct arbre_struct {
struct arbre_struct *gauche;
struct arbre_struct *droite;
union {
int op:2;
int val;
} opval;
} arbre_t;
int main() {
arbre_t *noeud;
arbre_t *racine = (arbre_t*)malloc(sizeof(arbre_t));
racine->opval.op = mul;
noeud = (arbre_t*)malloc(sizeof(arbre_t));
noeud->droite = NULL;
noeud->gauche = NULL;
noeud->opval.val = 7;
noeud->droite = noeud;
noeud = (arbre_t*)malloc(sizeof(arbre_t));
noeud->opval.op = plus;
noeud->gauche = noeud;
noeud = (arbre_t*)malloc(sizeof(arbre_t));
noeud->gauche = NULL;
noeud->droite = NULL;
noeud->opval.val = 5;
noeud->gauche->gauche = noeud;
noeud = (arbre_t*)malloc(sizeof(arbre_t));
noeud->gauche = NULL;
noeud->droite = NULL;
noeud->opval.val = 3;
noeud->gauche->droite = noeud;
printf("Arbre créé\n");
return 0;
}
Le programme crée un arbre représentant une expression arithmétique telle que vue par un compilateur après le processus d'analyse: les parenthèses sont superflues sous cette forme car le graphe de structure contient intrinsèquement cette information. Chaque nœud contient soit un opérateur arithmétique (plus, moins, multiplier ou diviser, défini par l'énumération operateurs) ou une valeur (entière) En notation explicite, l'expression représentée par la structure de données est (5+3)*7
Exécutez le programme (après avoir défini un point d'arrêt avant la fin, mais après avoir construit la structure de données), affichez l'élément racine et ouvrez tous les membres suivants en double-cliquant sur les membres gauche/droit de la structure. Vous pouvez récupérez toutes les informations sur la structure mémoire, mais elle ne semble pas très belle. Nous voulons obtenir un résultat similaire à la figure 4:
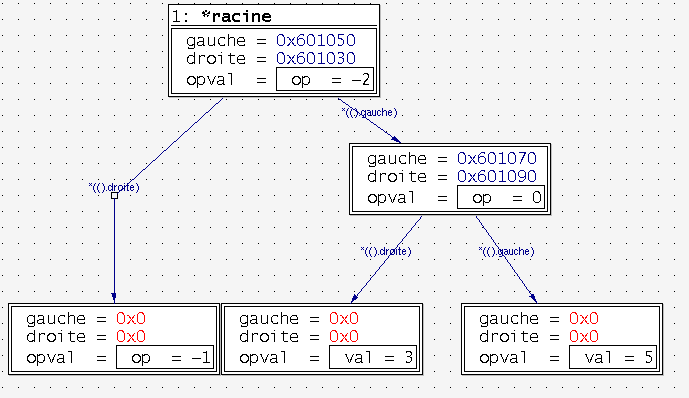
Figure 4: Représentation par un arbre d'une expression arithmétique simple
Un changement par rapport à la figure produite simplement en dépliant l'arbre est évident: tous les éléments sont alignés d'une façon ordonnée. Cela peut être réalisé assurément en utilisant la souris pour tirer les éléments vers leurs emplacements respectifs, mais ce n'est pas très pratique: une méthode beaucoup plus simple (du moins pour l'utilisateur) est la capacité de placement automatique de ddd. Pour l'utiliser, nous avons simplement besoin de sélectionner l'entrée menu (ou utiliser le raccourci ALT+Y) ddd dispose le graphique tel que vu ci-dessus.
Notez qu'une autre modification manuelle a été appliquée au graphe. Étant donné que nous utilisons une structure union pour représenter soit une valeur soit un opérateur dans tous les nœuds, ddd affiche à chaque fois les deux possibilités. Cela peut être source de confusion et cela doit être évité. Les règles sont claires: si les deux pointeurs gauche et droite contiennent la valeur NULL, le nœud représente un nombre, autrement c'est un opérateur. Sélectionnez "Undisplay" depuis le menu contextuel accessible avec le bouton droit de la souris pour effacer l'entrée indésirable. Ddd demandera si l'action doit être appliquée à toutes les structures correspondantes ou uniquement à la structure courante; puisque nous voulons effacer différentes valeurs dans différentes boites, le deuxième choix doit être appliqué.
Ddd propose plusieurs fonctionnalités supplémentaires en relation avec l'affichage du graphe dans le menu . Le lecteur devinera certainement très rapidement comment les utiliser car elles sont plutôt intuitives et parlent d'elle-mêmes.
Structures à liens multiples
Comme dernier exemple (et pour démontrer une fois de plus les immenses possibilités offertes par ddd), regardez la figure 5: elle représente un graphe produit par le programme poly.c qui implémente une représentation pour polynôme donné (3*x^2+zy-3xz^3) au moyen d'une structure de données présentée dans l'ouvrage de référence intemporelle sur l'informatique, Algorithmes Fondamentaux (issu de la série l'Art de la Programmation Informatique) de Donald Knuth. Vous n'avez pas besoin de comprendre immédiatement la signification du graphe... Laissez-vous simplement impressionner par la possibilité de de visualiser simplement des structures assez élaborées qui seraient simplement incompréhensibles à la seule vue du programme source. Notez que le placement automatique n'a pas été utilisé pour ce graphe, car il produit une bonne visualisation mais qui n'est pas très informative: beaucoup trop d'informations sur le sens derrière la structure sont ajoutées à la composition.
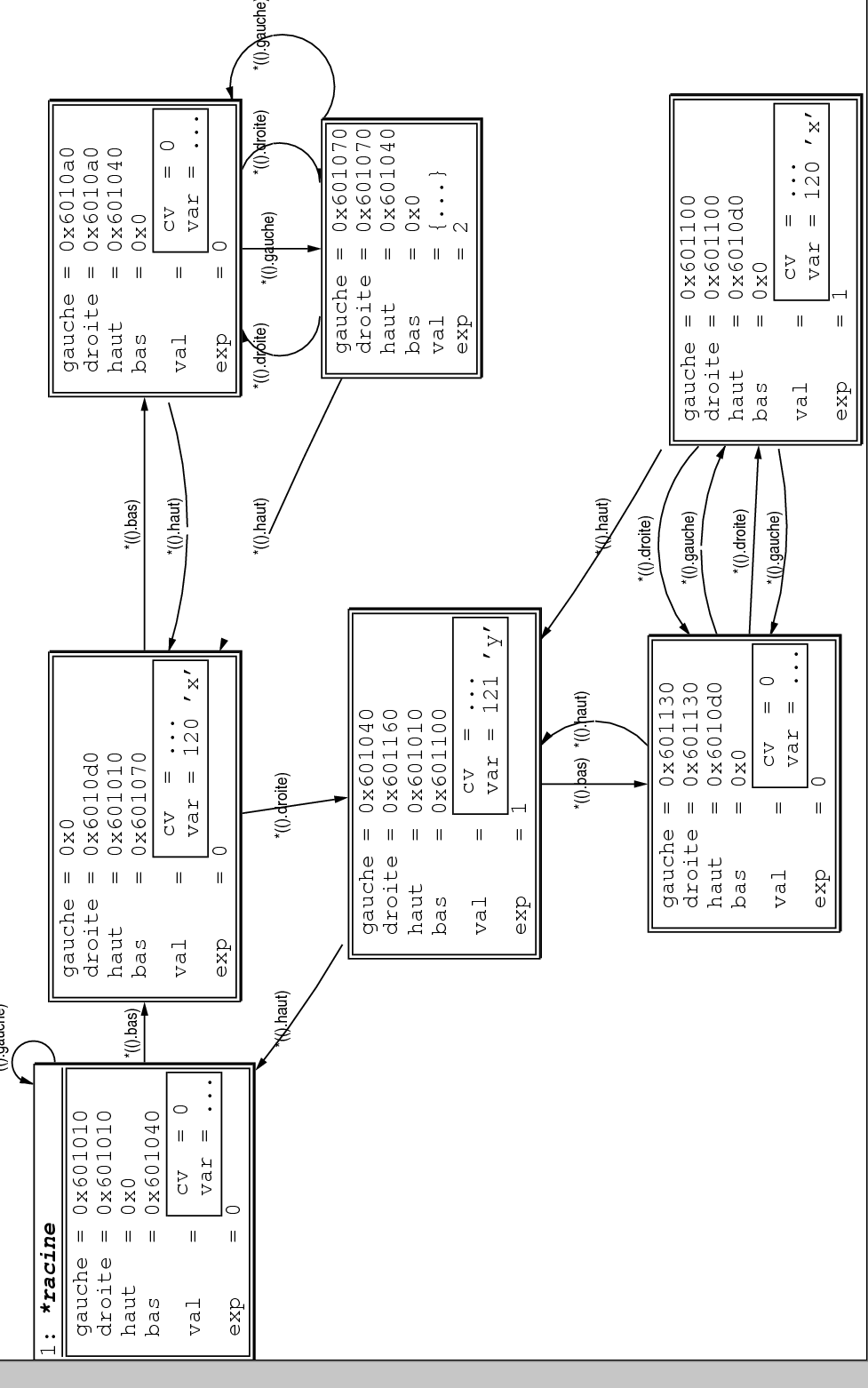
Figure 5: Représentation en mémoire d'une expression polynomiale
Traçage de jeux de données
Les structures des données ne sont pas les seuls objets que ddd est capable de dessiner: les jeux de données contenus dans les tableaux peuvent être visualisés grâce au célèbre programme Gnuplot
Le programme valtab.c est un programme qui crée une table de valeurs pour une fonction donnée (dans ce cas, une fonction sinus à deux dimensions).
Notez que vous devrez compiler ce programme avec l'option -lm de gcc pour inclure la bibliothèque mathématique!
#include <stdio.h>
#include <math.h>
int main() {
float *val;
float sval[100];
float **threed;
int points = 100;
float periode = 2*M_PI;
int compteur, compteur2;
val = (float*) malloc(points*sizeof(float));
for (compteur = 0; compteur < points; compteur++) {
val[compteur] = sin(compteur * periode/(float)points);
sval[compteur] = val[compteur];
}
threed = (float**)malloc(points*sizeof(float));
float x,y;
for (compteur = 0; compteur < points; compteur++) {
threed[compteur] = (float*)malloc(points*sizeof(float));
for (compteur2 = 0; compteur2 < points; compteur2++) {
x = compteur*periode/(float)points;
y = compteur2*periode/(float)points;
threed[compteur][compteur2] = 1.0f/(x+y)*sin(x+y);
}
}
/* Normalement, nous devrions écrire les données générées dans un fichier. */
printf("Tables de valeurs crées\n");
return 0;
}
Habituellement, la plupart des programmes traitent des fonctions plus compliquées (ou reçoivent leurs jeux de données par d'autres moyens), mais, dans tous les cas, le principe (remplir un tableau avec des valeurs) reste le même.
Nous utilisons trois types de tableaux dans notre programme d'exemple pour démontrer les différentes méthodes de traçage de données. La plus simple est un tableau statique unidimensionnel, tel que sval. Dans ce cas, nous devons simplement surligner l'identifiant en cliquant dessus avec le bouton droit de la souris et presser sur l’icône "plot" que l'on trouve dans la partie supérieure de la fenêtre — et voilà, une nouvelle fenêtre /application> avec le graphe désiré s'ouvre. L'apparence du graphe peut être personnalisée grâce aux différentes entrées du menu; la figure 6 montre la sortie avec le style de trace "Lines" au lieu du style par défaut "points" en sélectionnant dans le menu.
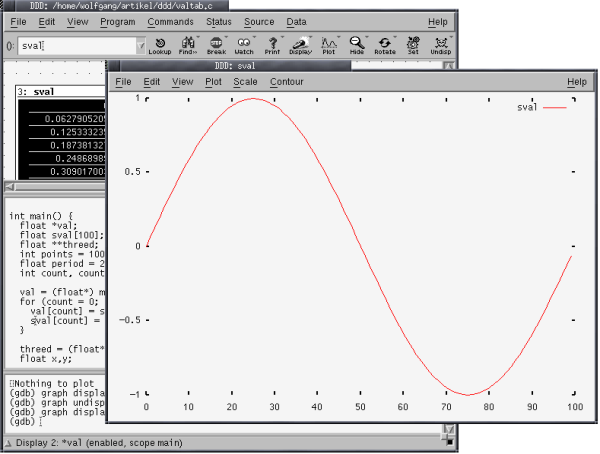
Figure 6: La fenêtre de tracé
La situation est un peu plus compliquée avec les tableaux créés dynamiquement, car ddd ne peut pas déterminer automatiquement leur longueur. Une astuce pour y parvenir consiste à utiliser ce que l'on appelle des tranches de tableaux qui doivent être définies manuellement dans la partie interactive du débogueur dans la partie inférieure de la fenêtre de ddd.
L'expression graph display val[0]@points crée une telle tranche de tableau, où l'expression de l'index [0] désigne la borne inférieure et @points désigne la borne supérieure les valeurs utilisées (à la place de la valeur en mémoire points, un simple nombre entier peut également être utilisé).
La trace de ce graphe s'obtient de la même façon que précédemment (en appuyant sur le bouton "trace") et on obtient (quelle surprise) le même résultat, puisque les mêmes jeux de données sont utilisés.
Le dessin de graphes en trois dimensions se fait presque de la même façon: l'identifiant du tableau statique ne nécessite que d'être sélectionné avec la souris afin d'appliquer ensuite le bouton "plot", tandis qu'une tranche de tableau doit être créée lorsque des structures allouées dynamiquement sont utilisées.
La syntaxe pour réaliser cela est graph display threed[0][0]@points@points, comme le lecteur l'aura supposé.
Les fonctionnalités de personnalisation disponibles avec gnuplot pour les graphes tridimensionnels ne sont pas bien gérés par l'interface de ddd, aussi les essais de traçage ne seront en général pas aussi bons et instructifs qu'avec les tracés en deux dimensions.
Imprimer les graphes et les tracés
Afin de documenter les programmes, il est parfois pratique d'avoir des représentations graphiques de leurs structures de données, comme celles générées par ddd. L'interface d'impression de ddd offre la possibilité de créer une version Postscript des graphes et des tracés. Pour imprimer un graphe, il suffit de sélectionner → . Un menu apparaît, proposant plusieurs choix, et l'appui sur le bouton d'impression produit soit un fichier soit envoi directement la sortie à l'imprimante.
La même approche peut être appliquée aux tracés; la seule différence étant que moins d'options sont disponibles dans la boite de dialogue pour l'impression. Alors que les graphes peuvent être exportés aussi bien vers le format Postscript que vers le format fig (utilisé par xfig, l'outil classique de dessin sous Unix), l'impression des tracés ne peut être exportée que vers Postscript.
Ddd apporte beaucoup plus de fonctionnalités telles que les points de surveillance, la gestion de plusieurs langages, etc. Elle sortent du cadre de cet article, puisque nous ne voulons pas répéter l'excellente documentation fournie avec ddd. (La documentation est disponible à http://www.gnu.org/software/ddd.) À la place, nous encourageons les lecteurs à explorer les riches fonctionnalités de ddd par eux-mêmes, en corrigeant leurs propres programmes.
En guise de conclusion, méditons sur une citation que ddd utilise en parmi ses "conseils du jour", car elle met parfaitement en évidence l'importance (et les limites) du débogage:
La débogueur ne remplace pas la réflexion judicieuse. Mais, dans certains cas, la réflexion ne remplace pas un bon débogueur. La combinaison la plus efficace et une bonne réflexion et un bon débogueur. [--Steve McConnell, Code Complete]
Wolfgang a écrit plusieurs articles dans des publications allemandes et internationales, il est l'auteur d'un livre en allemand sur le traitement de texte et travaille en tant qu'administrateur système et programmeur. Il s'intéresse principalement à la théorie des langage de programmation, les noyaux des systèmes d'exploitation (explicitement non limité à Linux..), et (parfois) à la physique. De plus, il est en croisade contre les logiciels monopolistes et propriétaires. Il vit actuellement à Londres.
Adaptation française de la Gazette Linux
L'adaptation française de ce document a été réalisée dans le cadre du Projet de traduction de la Gazette Linux.
Vous pourrez lire d'autres articles traduits et en apprendre plus sur ce projet en visitant notre site : http://www.traduc.org/Gazette_Linux.
Si vous souhaitez apporter votre contribution, n'hésitez pas à nous rejoindre, nous serons heureux de vous accueillir.