Gazette Linux n°102 — Avril 2004
Copyright © 2004 Justin Piszcz
Copyright © 2004 Joëlle Cornavin
Copyright © 2004 Encolpe Degoute
Article paru dans le n°102 de la Gazette Linux d'avril 2004
Cet article est publié selon les termes de la Open Publication License. La Linux Gazette n'est ni produite, ni sponsorisée, ni avalisée par notre hébergeur principal, SSC, Inc.
Table des matières
J'ai récemment acheté un disque dur Western Digital® de 250 Go, 8 Mo, 7200 tours/minute et je suis demandé quel système de fichiers journalisé je devrais utiliser. J'emploie actuellement ext2 sur mes autres disques durs plus petits. Lors d'un réamorçage ou d'un arrêt brutal, e2fsck met un certain temps sur les disques de seulement 40 à 60 Go. Par conséquent, je savais qu'un système de fichiers journalisé serait mon meilleur pari. La question est quelle est le meileur ? Pour pouvoir y répondre, j'ai procédé à des opérations courantes que les utilisateurs de Linux peuvent effectuer régulièrement au lieu de faire appel à des outils d'évaluation de performances tels que Bonnie ou Iozone. Je voulais une analyse d'évaluation de performances « concrète ». Une rapide analogie : juste parce l'Ethernet-Over-Power-Lines peut annoncer 10 Mbps (1,25 Mo/s), dans des tests réels, la vitesse maximale n'est que de 5 Mbps (625 ko/s). C'est pourquoi j'ai choisi d'exécuter mes propres tests plutôt que d'utiliser des outils d'évaluation de performances de disques durs.
COMPUTER: Dell Optiplex GX1
CPU: Pentium III 500MHZ
RAM: 768MB
SWAP: 1536MB
CONTROLLER: Promise ATA/100 TX - BIOS 14 - IN PCI SLOT #1
DRIVES USED: 1] Western Digital 250GB ATA/100 8MB CACHE 7200RPM
2] Maxtor 61.4GB ATA/66 2MB CACHE 5400RPM
DRIVE TESTED: The Western Digital 250GB.
LIBC VERSION: 2.3.2
KERNEL: linux-2.4.26
COMPILER USED: gcc-3.3.3
EXT2: e2fsprogs-1.35/sbin/mkfs.ext2
EXT3: e2fsprogs-1.35/sbin/mkfs.ext3
JFS: jfsutils-1.1.5/sbin/mkfs.jfs
REISERFS: reiserfsprogs-3.6.14/sbin/mkreiserfs
XFS: xfsprogs-2.5.6/sbin/mkfs.xfs
| 001] Création de 10 000 fichiers avec touch dans un répertoire. |
| 002] Exécution de find sur ce répertoire. |
| 003] Suppression du répertoire. |
| 004] Création de 10 000 répertoires avec mkdir dans un répertoire. |
| 005] Exécution de find sur ce répertoire. |
| 006] Suppression du répertoire contenant les 10 000 répertoires. |
| 007] Copie de l'archive (tarball) du noyau depuis un autre disque sur le disque de test. |
| 008] Copie de l'archive du noyau depuis le disque de test sur un autre disque. |
| 009] Exécution de untar sur l'archive du noyau sur le même disque. |
| 010] Exécution de tar sur l'archive du noyau sur le même disque. |
| 011] Suppression de l'arborescence des sources du noyau. |
| 012] Copie de l'archive du noyau 10 fois. |
013] Création d'un fichier de 1 Go depuis /dev/zero. |
| 014] Copie du fichier de 1 Go sur le même disque. |
| 015] Division d'un fichier de 10 Mo en blocs de 1 000 octets. |
| 016] Division d'un fichier de 10 Mo en blocs de 1 024 octets. |
| 017] Division d'un fichier de 10 Mo en blocs de 2 048 octets. |
| 018] Division d'un fichier de 10 Mo en blocs de 4 096 octets. |
| 019] Division d'un fichier de 10 Mo en blocs de 8 192 octets. |
| 020] Copie de l'arborescence des sources du noyau sur le même disque. |
021] Exécution de cat sur un fichier de 1 Go dans /dev/null. |
Note
Note :1 : entre chaque exécution de test, un sync et une mise en sommeil de 10 secondes ont été effectués.
Note 2 : chaque système de fichiers a été testé sur un système de fichiers créé proprement.
Note 3 : tous les systèmes de fichiers ont été créés en utilisant des options par défaut.
Note 4 : tous les tests ont été réalisés en ayant le démon cron tué et avec 1 utilisateur connecté.
Note 5 : tous les tests ont été effectués 3 fois et la moyenne a été prise. Tout test douteux a été réexécuté et vérifié avec la moyenne précédente pour des raisons de cohérence.
root@p500:~# mkfs.ext2 /dev/hdg1
mke2fs 1.35 (28-Feb-2004)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
30539776 inodes, 61049000 blocks
3052450 blocks (5.00%) reserved for the super user
First data block=0
1864 block groups
32768 blocks per group, 32768 fragments per group
16384 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 31 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
root@p500:~#
root@p500:~# mkfs.ext3 /dev/hdg1
mke2fs 1.35 (28-Feb-2004)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
30539776 inodes, 61049000 blocks
3052450 blocks (5.00%) reserved for the super user
First data block=0
1864 block groups
32768 blocks per group, 32768 fragments per group
16384 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 34 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
root@p500:~#
root@p500:~# mkfs.jfs /dev/hdg1 mkfs.jfs version 1.1.5, 04-Mar-2004 Warning! All data on device /dev/hdg1 will be lost! Continue? (Y/N) y \ Format completed successfully. 244196001 kilobytes total disk space. root@p500:~#
root@p500:~# ./mkreiserfs /dev/hdg1
mkreiserfs 3.6.14 (2003 www.namesys.com)
A pair of credits:
Nikita Danilov wrote most of the core balancing code, plugin infrastructure,
and directory code. He steadily worked long hours, and is the reason so much of
the Reiser4 plugin infrastructure is well abstracted in its details. The carry
function, and the use of non-recursive balancing, are his idea.
Lycos (www.lycos.com) has a support contract with us that consistently comes in
just when we would otherwise miss payroll, and that they keep doubling every
year. Much thanks to them.
Guessing about desired format.. Kernel 2.4.26 is running.
Format 3.6 with standard journal
Count of blocks on the device: 61048992
Number of blocks consumed by mkreiserfs formatting process: 10075
Blocksize: 4096
Hash function used to sort names: "r5"
Journal Size 8193 blocks (first block 18)
Journal Max transaction length 1024
inode generation number: 0
UUID: 8831be46-d703-4de6-abf3-b30e7afbf7d2
ATTENTION: YOU SHOULD REBOOT AFTER FDISK!
ALL DATA WILL BE LOST ON '/dev/hdg1'!
Continue (y/n):y
Initializing journal - 0%....20%....40%....60%....80%....100%
Syncing..ok
Tell your friends to use a kernel based on 2.4.18 or later, and especially not a
kernel based on 2.4.9, when you use reiserFS. Have fun.
ReiserFS is successfully created on /dev/hdg1.
root@p500:~# mkfs.xfs -f /dev/hdg1
meta-data=/dev/hdg1 isize=256 agcount=59, agsize=1048576 blks
= sectsz=512
data = bsize=4096 blocks=61049000, imaxpct=25
= sunit=0 swidth=0 blks, unwritten=1
naming =version 2 bsize=4096
log =internal log bsize=4096 blocks=29809, version=1
= sectsz=512 sunit=0 blks
realtime =none extsz=65536 blocks=0, rtextents=0
root@p500:~#
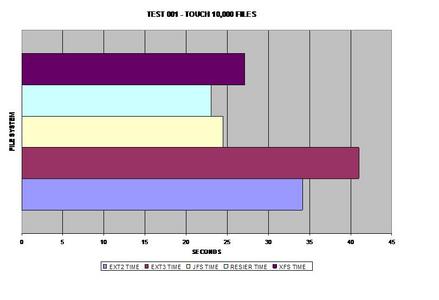
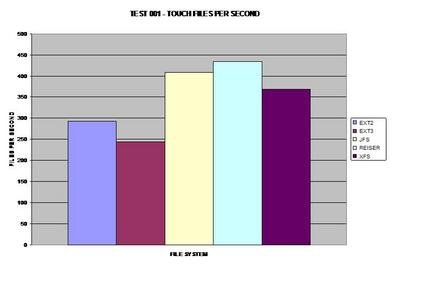
Dans le premier test, ReiserFS prend la tête, peut-être en raison de ses arbres de Bayer (B-Trees) équilibrés. (Si les images sont difficiles à lire sur votre écran, voici une archive tar contenant des versions agrandies de celles-ci.)
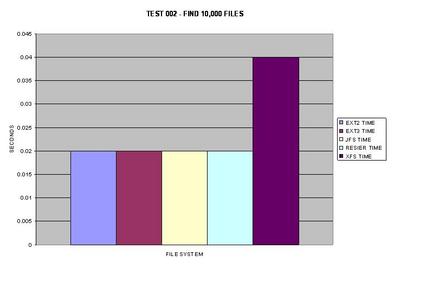
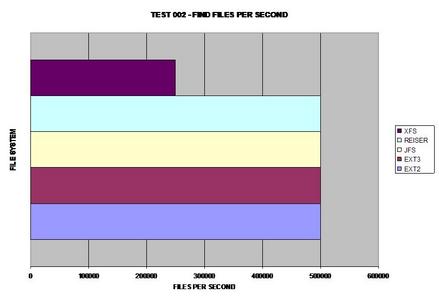
Tous les systèmes de fichiers se sont comportés de façon assez similaire lors de la recherche de 10 fichier dans un seul répertoire, la seule exception étant XFS qui a mis deux fois plus de temps.
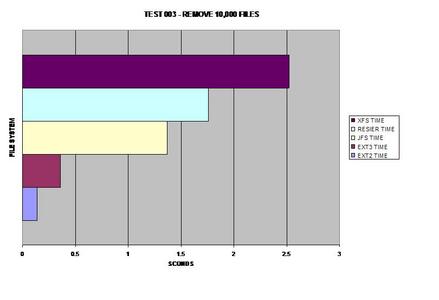
Les deux versions ext2 ext3 semblent récolter les bénéfices de la suppression de grands nombres de fichiers plus rapide que tout autre système de fichiers testé.
Pour être sûr que ce graphique était exact, j'ai refait l'évaluation du système de fichiers ext2 et obtenu pratiquement les mêmes résultats. J'ai été surpris de constater la quantité de taux de performances qu'ext2 et ext3 remportent l'un et l'autre pendant ce test.
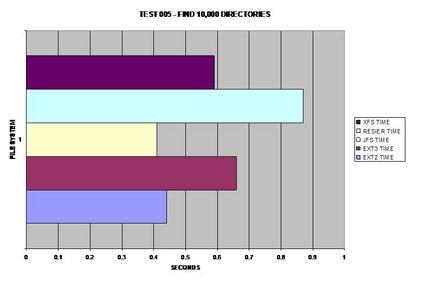
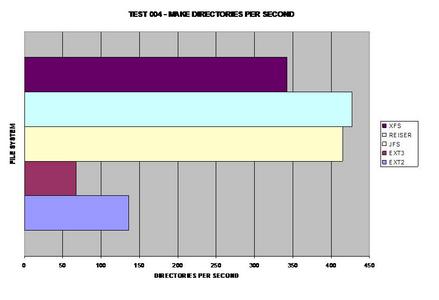
La recherche de 10 000 fichiers a semblé être identique, sauf pour XFS. Cependant, les répertoires sont les répertoires sont certainement gérés différemment selon les systèmes de fichiers testés. Assez curieusement, ReiserFS prend le plus grand taux de performances dans cette étape.
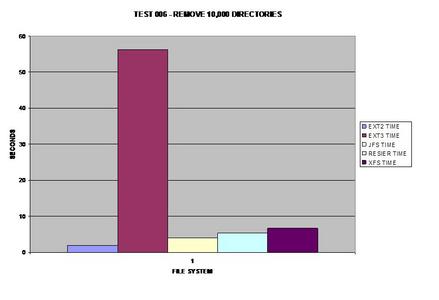
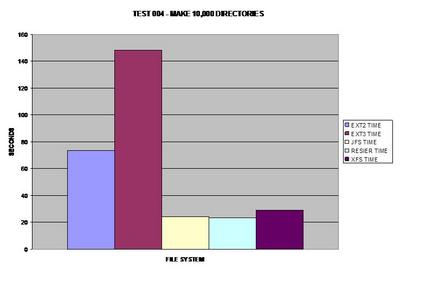
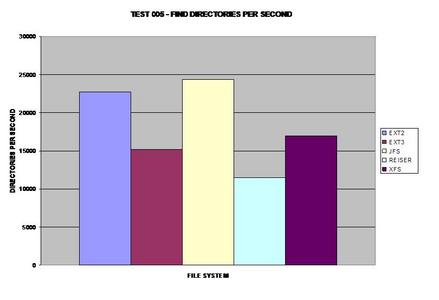
Tous les systèmes de fichiers se sont bien comportés dans cette étape, à l'exception de ext3. Je ne suis pas sûr de ce qui pourrait causer une telle surcharge pour ext3 par rapport à tous les autres systèmes de fichiers testés.
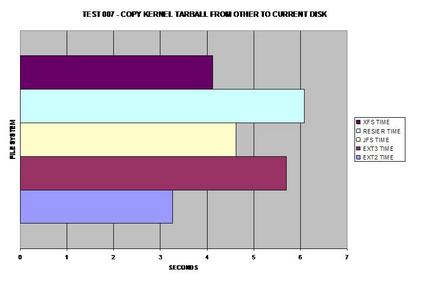
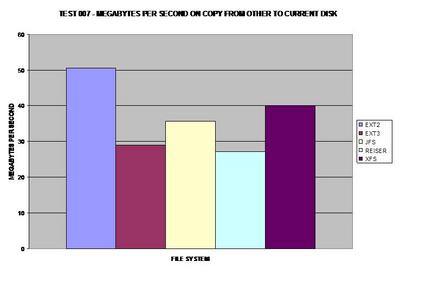
Comme prévu, ext2 gagne ici parce qu'il ne journalise aucune des données copiées. Comme beaucoup s'en doutent, XFS gère les fichiers volumineux de façon satisfaisante et prend la tête pour les systèmes de fichiers journalisés dans ce test.
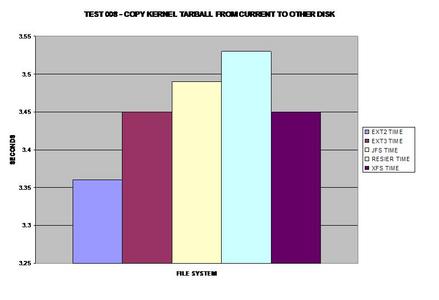
Ce banc de test représente la rapidité à laquelle l'archive (tarball) peut être lue depuis chaque système de fichiers. Étonnamment, ext3 rejoint la vitesse de XFS.
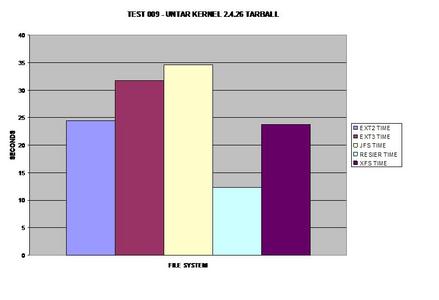
De façon surprenante, ReiserFS gagne, même par rapport au système de fichiers non journalisé ext2.
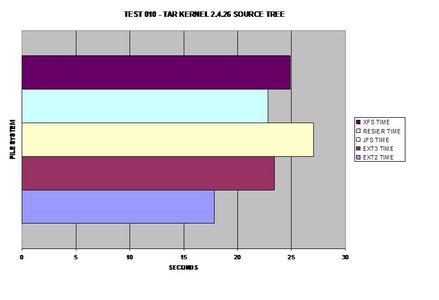
Le meilleur système de fichiers journalisé ici est ReiserFS. Cependant, ext3 le talonne à une seconde près.
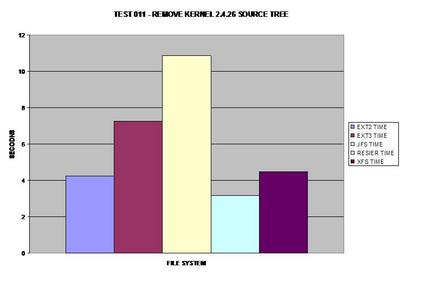
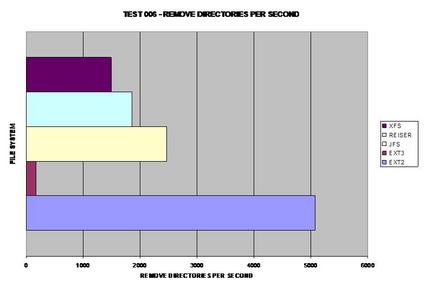
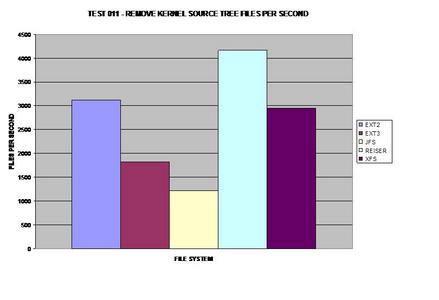
ReiserFS surprend encore une fois tout le monde et prend la tête. Il apparaît que JFS a de sérieux problèmes pour supprimer de grands nombres de fichiers et de répertoires.
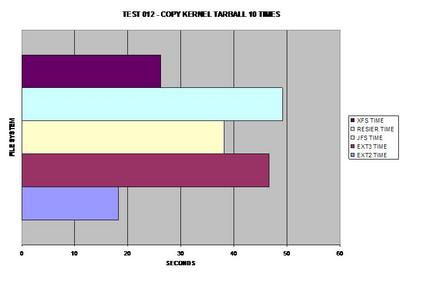
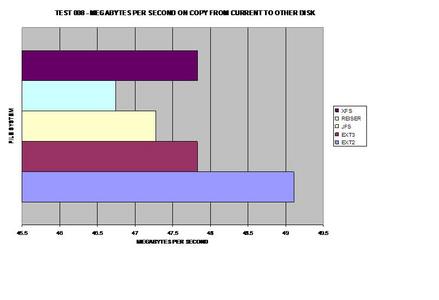
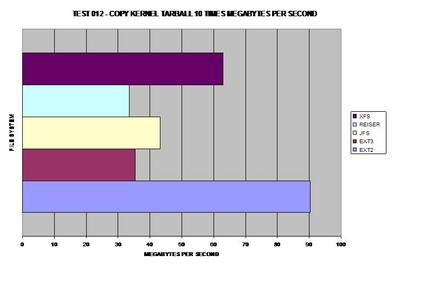
À l'évidence, ext2 est vainqueur ici et n'a pas besoin de journaliser ses copies de données mais XFS, tout à fait capable de gérer des fichiers volumineux aussi, le talonne à une seconde.

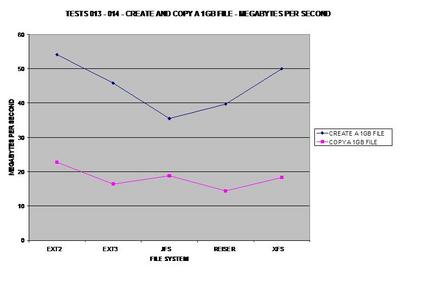
S'il y en a un qui doit traiter des fichiers volumineux de façon cohérente, XFS semble être le meilleur choix pour un système de fichiers journalisé.
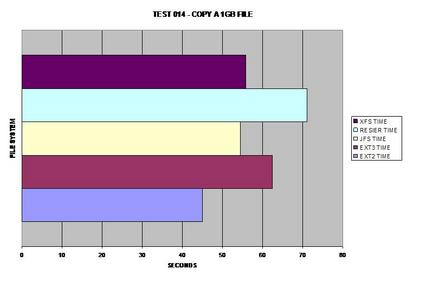
Une fois de plus côté journalisation, XFS se comporte parfaitement avec les fichiers volumineux. Néanmoins, JFS gagne d'un cheveu.
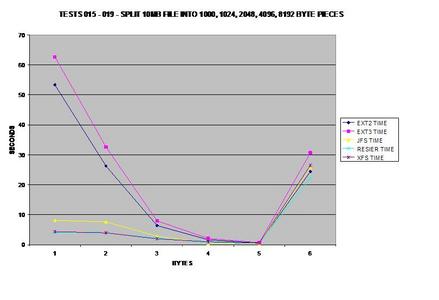
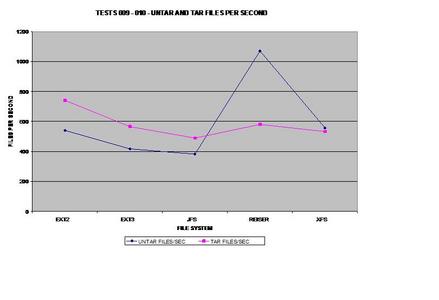
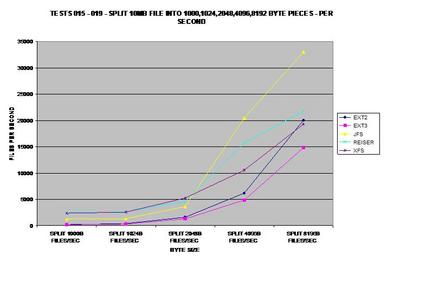
Ce test est certainement celui qui m'a le plus surpris, à tel point que je l'ai réexécuté plusieurs fois et que j'ai obtenu des résultats cohérents à chaque fois. ext2 et ext3 ont de sérieuses difficultés à scinder des fichiers en petits blocs, alors que JFS, ReiserFS et XFS ne semblent pas avoir de problème.
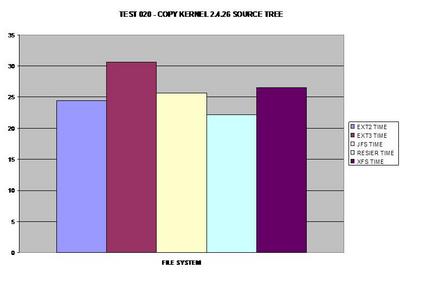
J'ai supposé que les utilisateurs demanderaient ce test si je ne le faisais pas, le voici donc. Il apparaît que l'arbre de Bayer de ReiserFS permet de surpasser tous les systèmes de fichiers testés, y compris ext2 !
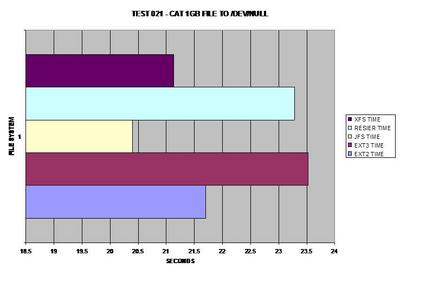
JFS a un succès foudroyant sur cette évaluation de performances. J'ai été étonné qu'il se soit effectué aussi bien. Cependant, en traitant à nouveau des fichiers volumineux, XFS le suit de près.
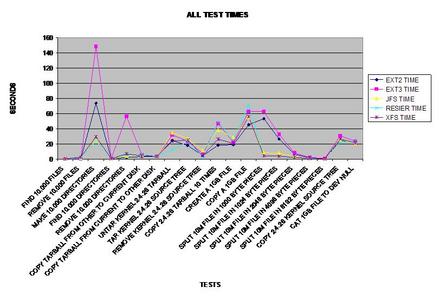
Voici un graphique linéaire représentant tous les temps des tests.
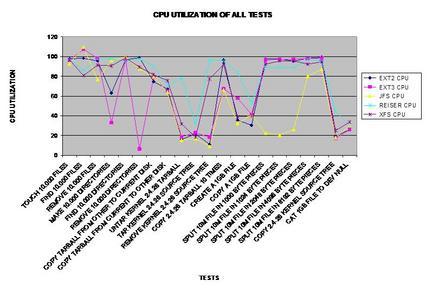
Voici un graphique linéaire représentant le processeur utiisé pendant chaque test.
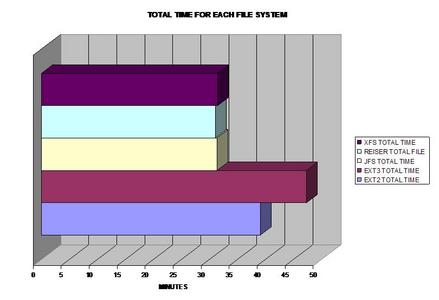
Un graphique en barres pour tous les tests synchronisés.
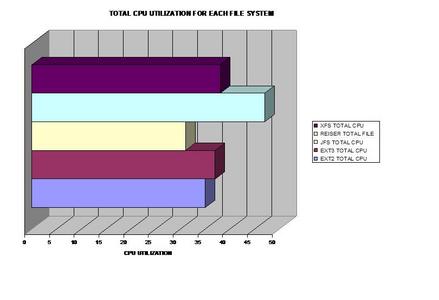
Un graphique en barres de l'utilisation des processeurs combinés.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.

Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
Ce graphique a été calculé par les test précédents.
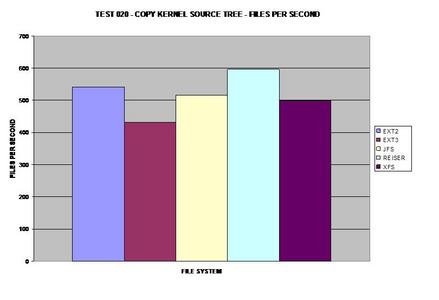
Ce graphique a été calculé par les test précédents.
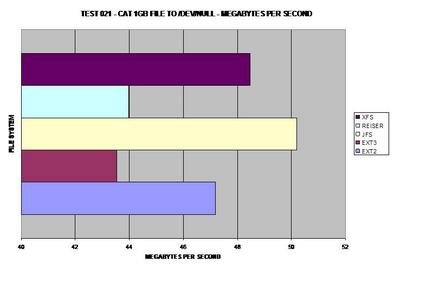
Ce graphique a été calculé par les test précédents.
Pour ceux d'entre vous qui veulent en savoir davantage, la conclusion s'impose évidemment avec Temps total pour tout le test d'évaluation des performances. Le meilleur système de fichiers journalisé à choisir d'après ces résultats serait JFS, ReiserFS ou XFS selon vos besoins et les types de fichiers que vous traitez. J'ai été très surpris de la lenteur d'ext3 en général, car beaucoup de distributions utilisent ce système de fichiers comme système de fichiers par défaut. En général, il faudrait choisir le meilleur système de fichiers d'après les propriétés des fichiers qu'ils traitent pour les meilleures performances possibles !
Adaptation française de la Gazette Linux
L'adaptation française de ce document a été réalisée dans le cadre du Projet de traduction de la Gazette Linux.
Vous pourrez lire d'autres articles traduits et en apprendre plus sur ce projet en visitant notre site : http://www.traduc.org/Gazette_Linux.
Si vous souhaitez apporter votre contribution, n'hésitez pas à nous rejoindre, nous serons heureux de vous accueillir.