Par Carlos Serrao carlos.serrao@adetti.iscte.pt
DES a été utilisé pendant longtemps pour assurer la confidentialité des transactions dans les environnements de communication ouverts, tout particuličrement dans les milieux financiers et bancaires. Cependant, le niveau de sécurité que garantit cet algorithme n'est plus ce qu'il était. Les conditions d'utilisation de DES se sont transformées au fil de la croissance exponentielle d'Internet. Ce qui était considéré comme sűr il y a 10 ans ne l'est plus maintenant. Le but de cet article est de démontrer ŕ quel point la robustesse de DES n'en est pas une en réalité et cela en explicitant comment un assaillant déterminé peut le casser en utilisant le langage de programmation Java et le systčme d'exploitation Linux.
La cryptographie a depuis toujours été utilisée comme une maničre efficace de protéger des informations sensibles des regards non-autorisés et curieux. Elle a suivi un essor exponentiel lors de la Seconde Guerre Mondiale. Tant les Alliés que les Nazis et les Japonais ont utilisé cette technique avec succčs. Ŕ simplement parler, la cryptographie est un procédé qui permet d'assurer la confidentialité des communications. Parmi les différents problčmes soulevés en cryptographie, on distingue principalement le cryptage et le décryptage. Des écueils tels que les signatures et les certificats numériques sont tout aussi importants. De nos jours, deux types différents de cryptographie sont utilisés : ŕ clé secrčte ou cryptographie symétrique et ŕ clé publique ou cryptographie asymétrique. La différence la plus importante entre les deux tient dans l'utilisation de la clé. Dans le premier cas, une seule clé est utilisée ŕ la fois pour le cryptage et le décryptage. Dans le second cas, deux clés différentes sont utilisées : une pour le cryptage, une autre pour le décryptage. Normalement, la clé publique est librement disponible alors que la clé privée est gardée secrčte. Toute la sécurité des systčmes ŕ clé publique repose sur la confidentialité de la clé privée. Dans cet article, nous allons principalement porter notre attention sur le premier cas, la cryptographie ŕ clé secrčte. DES n'est qu'un des algorithmes qui utilisent celle-ci. D'autres, tels que IDEA (Algorithme de Cryptage de Données International ou International Data Encryption Algorithm), RC2 (Ron's Code 2) ou RC5 (Ron's Code 5) y recourent aussi. DES (Norme de Cryptage de Données ou Data Encryption Standard) est un algorithme de chiffrement par bloc qui a été défini et adopté par le gouvernement des Etats-Unis en 1977 comme norme officielle. Il a été ŕ l'origine développé par IBM en 1970 sous le nom de LUCIFER et a été rapidement adopté comme le systčme cryptographique le plus utilisé dans le monde. [1] Les banques et les institutions financičres utilisent principalement DES.
Le but principal de la cryptographie est de garder secrčtes des informations vis-ŕ-vis de personnes non-autorisées. La cryptanalyse est un sous-domaine de la cryptographie qui tente de briser la confidentialité (trouver le texte originel ŕ partir du texte crypté sans en connaître la clé de cryptage). Une cryptanalyse réussie est en mesure de trouver ŕ la fois le texte originel et la clé utilisée. Plusieurs méthodes permettent d'attaquer ces algorithmes. Le succčs ou l'échec de chacune des méthodes d'attaque est fortement lié ŕ la quantité d'informations que l'attaquant peut obtenir ŕ la fois sur le texte crypté et sur le texte en clair. [2] En voici quelques unes parmi les plus utilisées :
Le problčme de la robustesse des clés est depuis toujours âprement discuté. Plus la clé cryptographique est longue, plus le texte chiffré devient inviolable. Mais dans ce cas, le systčme de cryptographie devient plus gourmand en puissance de calcul.
|
Année | Millions de cryptages par seconde |
| 1995 | 4 |
| 2000 | 32 |
| 2005 | 256 |
|
Taille de la clé | 1995 | 2000 | 2005 |
| 40 bits | 68 secondes | 8,6 secondes | 1,07 secondes |
| 56 bits | 7,4 semaines | 6,5 jours | 19 heures |
| 64 bits | 36,7 années | 4,6 années | 6,9 mois |
| 128 bits | 6,7e17 Mannées | 8,4e16 Mannées | 1,1e16Mannées |
|
|
|
Année | Millions de cryptages par seconde |
| 1995 | 50 |
| 2000 | 400 |
| 2005 | 3200 |
|
Taille de la clé | 1995 | 2000 | 2005 |
| 40 bits | 1,3 jours | 3,8 heures | 28,6 minutes |
| 56 bits | 228 années | 28,6 années | 3,6 années |
| 64 bits | 58,5 Mannées | 7,3 Mannées | 914 années |
| 128 bits | 1,1e12 Mannées | 1,3e30 Mannées | 1,7e19 Mannées |
|
|
La robustesse des clés dépend beaucoup de la capacité de traitement disponible. Plus la puissance de calcul sera importante, plus le temps nécessaire pour casser un encryptage sera réduit. Par contre, si la capacité de traitement augmente, la taille de la clé également, ce qui tend ŕ tirer vers le haut la robustesse des algorithmes de cryptographie. En tout cas, ce qui semble clair, c'est que les clés que nous considérions comme sűres il y a deux ou trois ans ne le sont plus du tout maintenant.
En 1972, le Comité National des Normes [NdT : National Bureau of Standards, plus connu sous le nom de NIST] a émis une requęte en direction de la communauté scientifique dans le but de concevoir un nouvel algorithme de cryptage. Ce nouvel algorithme devait avoir les caractéristiques suivantes :
En 1974, IBM donna une réponse ŕ cette requęte avec un algorithme du nom de LUCIFER (plus tard, il prit le nom de DEA - Algorithme de Cryptage de Données ou DES). Finalement, en 1976, DES fut adopté aux États-Unis comme norme.
DES est depuis 20 ans une norme internationale. Bien qu'il commence ŕ montrer des signes d'essoufflement, il est encore considéré comme l'un des algorithmes les plus robustes et efficaces au monde.
DES est un algorithme de chiffrement par bloc. Il encrypte les données par blocs de 64 bits. Un échantillon de 64 bits de texte en clair entre dans l'algorithme et il en sort un bloc de 64 bits de texte chiffré.
C'est un algorithme ŕ clé symétrique qui utilise la męme pour l'encryptage et le décryptage. Sa taille est de 56 bits (sur les 64 bits effectifs, un sur huit sert au contrôle de parité).
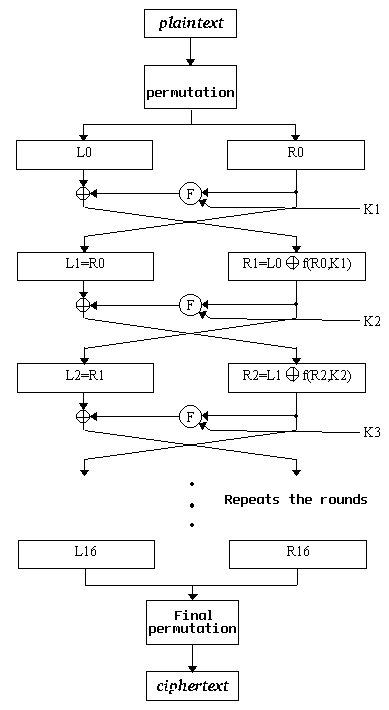
Ŕ son niveau le plus élémentaire, l'algorithme est basé sur deux principes simples : la diffusion et la confusion. DES applique des substitutions suivies de permutations au texte en clair, cela selon une clé donnée. Ce procédé s'appelle un round et DES l'applique 16 fois. Le schéma qui suit représente une vue plus détaillée de DES.
Un schéma détaillé du fonctionnement de DES
Une explication plus détaillée sort du cadre de cet article. Vous pourrez trouver plus d'informations dans n'importe quel bon livre sur la cryptographie.
La Division de Sécurité des Données des RSA Laboratories promeut et maintient un ensemble de concours de cryptographie dans une optique de recherche [3] Parmi ces concours mis en place par RSA, il y a :
Le concours DES a été originellement lancé en Janvier 1997 dans le but de démontrer que la sécurité sur 56 bits, telle que celle qui est offerte par le DES du gouvernement des USA, n'offre qu'une faible protection contre un adversaire déterminé. Cela s'est confirmé quand la clé secrčte utilisée pour le cryptage fut trouvée le 17 juin 1997. Depuis, il est généralement admis que des tentatives de recherche exhaustive plus rapides sont possibles : c'est d'ailleurs le but du concours DES II de montrer ŕ quel point.
Alors que le premier a démontré que DES était craquable par le biais d'une attaque par recherche exhaustive, le but du nouveau concours DES est de voir ŕ quelle vitesse une telle attaque peut ętre menée, dans le but de juger la vulnérabilité réelle de DES.
Deux fois par an, le 13 janvier et le 13 juillet, ŕ 9 heures du matin, (Pacific Time), un nouveau concours est présenté sur la page de RSA. Le concours consiste en un texte chiffré produit par le cryptage DES d'un texte en clair inconnu doté d'une en-tęte fixée et connue. Le premier ŕ trouver la clé gagne, le montant de la récompense dépendant de la vitesse ŕ laquelle la clé a été trouvée.
Pour chaque concours, le message inconnu est précédé de trois blocs de texte connus contenant la phrase de 24 caractčres : The unknown message is:. Alors que le texte mystčre en clair qui suit n'est connu que de quelques employés de RSA Data Security, la clé secrčte effectivement utilisée pour le cryptage est générée aléatoirement et détruite au sein męme du logiciel de génération du concours. La clé n'est jamais révélée ŕ quiconque.
Le but de chaque concours est de trouver la clé secrčte générée aléatoirement et utilisée lors du cryptage dans un temps plus court que celui atteint lors des précédentes éditions.
De nombreux problčmes nécessitent une grosse puissance de calcul pour trouver la solution. Certains d'entre eux, cependant, peuvent ętre parallélisés ŕ l'extręme et, avec l'étendue d'Internet de nos jours, il est possible d'étendre ŕ un point jusqu'alors inimaginable la portée de n'importe quel entreprise ŕ grande échelle.
Casser DES fait partie de ces problčmes. Il est nécessaire de recourir ŕ une puissance de calcul massivement parallčle relativement importante. Męme si nous ne considérons qu'une clé de 56 bits, c'est une tâche trčs difficile ŕ accomplir.
La meilleure stratégie pour y parvenir est d'utiliser la maničre forte. Ceci demande de tester toutes les clés possibles puis d'analyser et de comparer les résultats. Si nous considérons une clé de 56 bits, cela veut dire que nous aurons approximativement 256 combinaisons possibles. Męme avec la puissance de calcul dont nous disposons de nos jours, cela va prendre un moment.
Casser DES est clairement un problčme NP-complet. Il est impossible d'y trouver une solution en un temps polynomial mais, si l'on dispose d'une solution, on peut savoir si elle est valide. Typiquement, tous les problčmes cryptographiques sont des problčmes NP-complets.
Le premier aspect ŕ considérer lorsque l'on conçoit une architecture générale pour casser DES est de choisir entre une attaque matérielle ou logicielle.
DES peut ętre trčs facilement implanté sur une puce et l'on peut en utiliser un grand nombre pour le casser. L'un des avantages les plus évidents de cette approche est sa puissance de calcul résultante. D'un autre côté, un des problčmes causé par cette architecture est son trčs grand coűt.
L'autre option, l'attaque logicielle, pose entre autres problčmes celui du coűt en puissance de calcul. Si l'on n'utilise qu'un seul ordinateur, la puissance de traitement obtenue sera plutôt décevante. Ce type d'attaque est trčs facile ŕ implanter et est également moins coűteux que le précédent.
Cependant, on peut obtenir des résultats plus intéressants en utilisant une attaque par calcul distribué qui se base sur l'augmentation de la puissance de traitement qu'engendre le cumul des puissances de calcul de plusieurs ordinateurs.
L'informatique distribuée peut se décrire facilement comme la mise en commun de multiples machines en réseau de telle maničre que les informations ou les autres ressources puissent ętre partagées entre tous les ordinateurs connectés. Le but final est d'essayer de mettre en place ce partage sur une grande échelle, pour de nombreuses machines et de nombreux utilisateurs, et les unifier en un systčme cohérent.
Elle est devenue un sujet d'études quand le matériel informatique a évolué des gros systčmes (mainframe), sur lesquels tout le monde partageait les ressources d'une machine unique, vers les mini-ordinateurs. Ceux-ci ont contraint deux personnes (ou deux programmes) ŕ collaborer ou ŕ partager des ressources quand ils se trouvaient sur des machines différentes. C'est le but de l'informatique distribuée que de coordonner ce travail ou de donner accčs ŕ ces ressources.
L'intéręt pour cette branche s'est encore accru avec l'avčnement des stations de travail individuelles et des PCs en réseau, principalement du fait du développement d'Internet. Compte tenu du fait qu'il s'agit lŕ de machines mono-utilisateur, le besoin de partager des informations, des ressources de calcul ou de données s'est fait sentir dčs qu'un travail de collaboration a vu le jour.
Comme il a été dit plus haut, une des maničres envisageables de concevoir une architecture destinée ŕ casser DES est de la penser en termes d'informatique distribuée.
Cependant, il convient de prendre en compte quelques considérations. Par exemple, quelle est la meilleure configuration ŕ adopter et quelles en sont les contraintes.
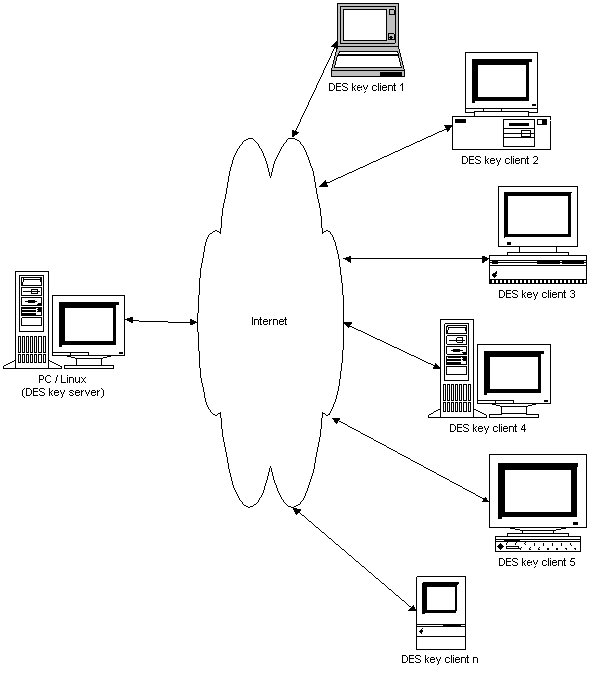
Il ne fait aucun doute que pour profiter de la disponibilité de la puissance de calcul d'Internet, la meilleure solution est d'implanter une architecture client-serveur classique. Un serveur chargé de la distribution des clés et des clients pour faire le sale boulot : tester toutes les clés et vérifier les résultats.
Aperçu de l'architecture distribuée
Plusieurs approches différentes sont possibles pour conduire une recherche exhaustive. Le point le plus important ŕ considérer est de savoir si la recherche est coordonnée par un serveur central ou si de multiples processus partent de positions aléatoires dans l'espace de recherche et tournent indépendamment jusqu'ŕ ce qu'une clé soit trouvée.
L'utilisation d'un serveur central peut poser quelques problčmes. Non seulement est-ce un point de panne central, mais aussi risque-t-on des congestions ou des erreurs du réseau.
Un certain nombre de précautions doivent aussi ętre prises en compte. Les serveurs peuvent ętre mis en réseau de maničre hiérarchique ou alors ils peuvent ętre répliqués si les ressources le permettent, auquel cas les points de panne potentielle sont moins catastrophiques. Par ailleurs, les clients peuvent eux-męmes effectuer des tests de maničre ŕ quelque peu se prémunir des dysfonctionnements. Par ailleurs, pour se garder des clients mal intentionnés, les serveurs peuvent effectuer des tests plus poussés sur eux. Le serveur peut leur demander de fournir un rapport sur les problčmes qu'il aura pu engendrer, et qui peuvent ętre vérifiés pour un coűt de traitement trčs bas. Alternativement, un client pourrait calculer une somme de contrôle sur toutes les solutions qu'il a tentées dans le domaine examiné et un autre client serait alors en mesure de le contrôler.
En dépit des problčmes posés par une architecture client-serveur, cela reste la plus facile et la moins chčre des solutions ŕ implanter et ŕ maintenir.
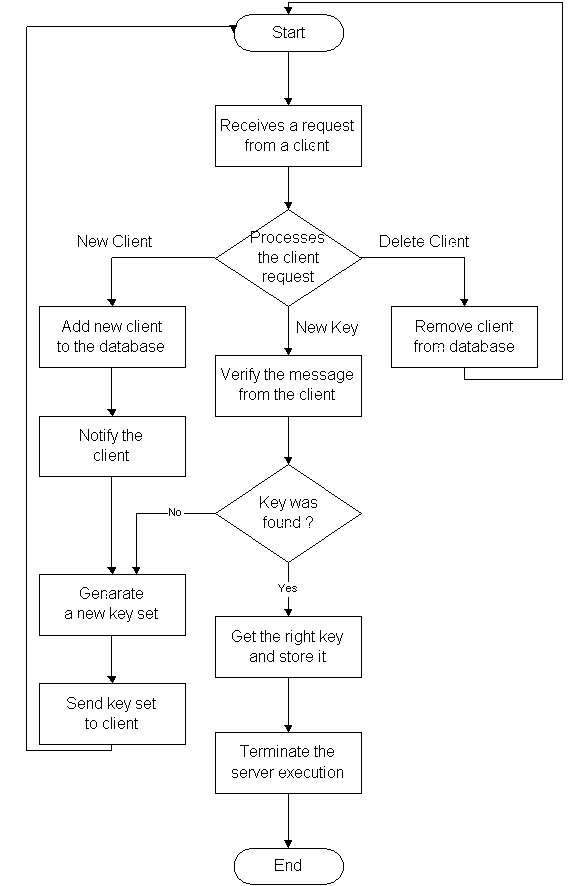
L'idée de base est d'avoir un serveur central qui a la charge de tâches simples comme ajouter de nouveaux clients dans le groupe, distribuer de nouveaux jeux de clés ainsi que vérifier et mettre ŕ jour les résultats.
Le serveur lui-męme se contente de faire un travail facile sur le systčme. Le sale boulot, essayer toutes les clés possibles et vérifier les résultats, est fait par l'ensemble des clients. Plus il y a de clients dans le systčme, plus vite l'espace de recherche de la clé sera couvert.
On peut aisément résumer les fonctionnalités offertes avec le schéma suivant.
Fonctionnalités d'un serveur de clé DES
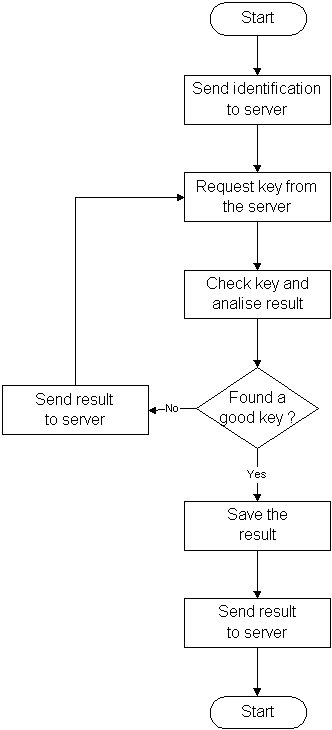
Les fonctionnalités offertes par le client peuvent également se résumer de cette maničre :
En gros, la principale fonction du logiciel client est de tester toutes les clés possibles dans l'échantillon fourni par le serveur puis d'analyser les résultats afin de déterminer si la clé est la bonne.
Si c'est le cas, le client entre en communication avec le serveur et l'en avertit.
Fonctionnalités d'un client de clé DES
Il ne fait plus aucun doute que la meilleure architecture envisageable pour relever le défi DES, c'est d'utiliser une architecture distribuée client-serveur sur Internet.
Pour pouvoir en implanter une, des décisions primordiales doivent ętre prises, parmi lesquelles le choix des meilleures plates-formes de déploiement et celui des bons outils.
Linux est un systčme d'exploitation compatible Posix destiné ŕ tourner sur architecture Intel. Le systčme dispose aussi d'extensions pour satisfaire aux exigences du System V et de BSD.
Cet OS est distribué sous la licence GNU Public license et, en tant que tel, est librement distribuable dans la mesure oů le code source accompagne la distribution ou, ŕ défaut, est au minimum accessible ŕ l'utilisateur.
Linux tourne sur les processeurs Intel 386 et ultérieurs capables d'utiliser le mode protégé du 386.
Pour une implantation vraiment minimum, il va vous falloir 10 ŕ 15 Mo de disque dur et 8Mo de RAM. Il est possible de faire tourner Linux avec 4Mo mais 8 est le minimum raisonnable pour une installation en mode texte. Pour pouvoir utiliser X, attendez vous ŕ avoir besoin d'au moins 16 Mo de RAM (et 300M sur votre disque dur).
Le systčme est actuellement capable de compiler et d'exécuter des programmes Unix compatibles Posix. Les programmes DOS pourront tourner avec DosEmu. Quant aux applications Windows, certaines pourront fonctionner par le biais de Wine, un émulateur de Windows [NdT : WINE signifie Wine Is Not an Emulator d'aprčs ses développeurs ;-)].
Bien que Linux soit habituellement lié aux machines 386/486/Pentium, il tourne, ou est en cours de portage, sur d'autres architectures (comme DEC Alpha, Sun SPARC, MIPS, PowerPC et PowerMAC) [NdR: et en version réduite sur certains microcontrôleurs, comme le Dragonball des Palm Pilots].
Java est un langage de programmation orienté objet développé par Sun Microsystems et qui est maintenant ŕ la charge de sa filiale JavaSoft.
Au premier abord, cela ressemble ŕ du C et ŕ du C++, mais sous le capot, c'est différent. Java est un langage ŕ la fois compilé et interprété. Le code source est compilé dans un format universel (du code objet pour la machine virtuelle) qui peut ętre facilement transporté via Internet puis interprété sur de nombreuses plate-formes.
En comparaison des autres langages de programmation, Java est plus simple, plus robuste et plus rapide d'accčs. Il permet de développer une application avec un déboguage minimal et il est instantanément portable sur de nombreux systčmes d'exploitation. En comparaison des autres solutions Internet, Java offre des performances et une polyvalence inégalées tout en minimisant la pression sur les serveurs web en répartissant la charge du traitement sur les machines client.
Java dispose aussi d'un certain nombre d'API (Application Programming Interface ou Interface de Programmation d'Application) qui facilitent le développement rapide d'applications complexes. Parmi ces APIs, on peut pour le moment citer le Réseau, les Appels de Méthode en Environnement Distribué, les Connexions aux Bases de Données et le support de la cryptographie.
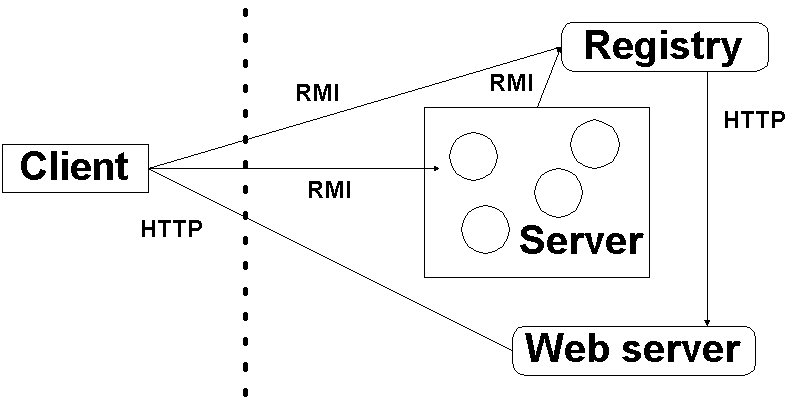
La technologie Java RMI (Remote Method Invocation ou Invocation Distante de Méthode) est la base de l'informatique distribuée dans l'environnement Java. Compte tenu du fait que Java RMI a été conçu aprčs l'adoption en masse d'Internet et de la conception orienté-objet, les développeurs ont ŕ leur disposition un environnement flexible et dynamique pour la construction d'applications distribuées.
Le comportement de la technologie Java RMI dans le cadre d'une application distribuée
Par le biais de la technologie Java RMI, les développeurs peuvent désormais :
JDBC (Java Database Connectivity ou API Java de Connexion aux Bases de Données) est une spécification d'API pour la connexion des programmes écrits en Java aux bases de données répandues. L'API vous permet d'encoder les requętes d'accčs écrites en SQL (Structured Query Language ou Langage de Requęte Structuré) qui sont alors passées au programme qui gčre la base de données. Il renvoie les résultats par une interface similaire. JDBC est trčs proche de la norme ODBC (Open DataBase Connectivity ou API Ouverte de Connexion aux Bases de Données) de Microsoft et, avec un petit pont logiciel, vous pouvez utiliser l'interface JDBC pour accéder ŕ des bases de données ŕ travers l'interface ODBC de Microsoft. Par exemple, il vous est possible d'écrire un programme destiné ŕ accéder ŕ de nombreux moteurs de bases de données sur de multiples plate-formes d'exploitation. Lors de l'accčs ŕ une base de données sur un PC faisant tourner Windows 95 de Microsoft et une base de données Microsoft Access, votre programme ŕ base de requętes JDBC serait en mesure d'accéder ŕ la base de données Microsoft Access.
JDBC propose en fait deux niveaux d'interface. En marge de l'interface principale, il existe également une API pour qu'un gestionnaire JDBC communique avec des moteurs de base de données particuliers, avec le pont JDBC-ODBC si nécessaire et avec un pilote JDBC réseau si le programme Java est exécuté dans un environnement réseau (ŕ savoir qu'il accčde ŕ une base de données distante).
Lorsqu'il accčde ŕ une base de données distante, JDBC tire parti du schéma d'adressage de fichier d'Internet, ce qui fait qu'un nom de fichier ressemble ŕ une adresse de page web (ou ŕ une URL (NdT : ce qui paraît normal en vertu du fait que les pages web sont désignées par des URL!)). Par exemple, un requęte SQL Java pourrait identifier la base de données de la maničre suivante :
jdbc:odbc://www.somecompany.com:400/databasefile
JDBC spécifie un ensemble de classes ŕ la disposition de l'utilisateur pour la construction des requętes SQL. Un autre ensemble de classes décrit l'API du pilote JDBC. Les types de données SQL les plus courants, convertis en des types de données Java, sont également gérés. L'API offre le support spécifique ŕ l'implantation des requętes transactionnelles ainsi que la possibilité de valider (commit) ou d'annuler (roll back) une transaction.
Le Module de Cryptographie Java (Java Cryptography Extension (JCE)) étend l'API de l'Architecture de Cryptographie Java (Java Cryptography Architecture (JCA)) avec des ajouts concernant le support du cryptage et de l'échange de clés.
Le JCE est un ensemble d'API et d'implantation de fonctionnalités cryptographiques qui comprennent le cryptage par bloc, de flux, symétrique comme asymétrique. Il vient en renfort des fonctionnalités de sécurité des JDK 1.1.x / JDK 1.2 Java qui eux-męmes incluent les signatures numériques (DSA) et les message digests (MD5, SHA).
L'architecture du JCE suit les męmes principes de conception que ceux qui sont mis en place dans la JCA.
Les Systčme de Gestion de Bases de Données Relationnelles (SGBDR ou relational database management systems (DBMSs)) traditionnels gčrent des modčles de données constitués de collections de relations nommées qui contiennent des attributs d'un certain type.
Dans les produits actuels du commerce, on dénombre comme types possibles les nombres flottants, les entiers, les chaînes de caractčre, les devises et les dates. Il est généralement admis que ce modčle n'est pas adapté ŕ un traitement ultérieur par des applications de traitement des données. Le modčle relationnel a remplacé avec succčs les modčles précédents partiellement en vertu de sa simplicité spartiate. Cependant, comme nous l'avons déjŕ mentionné, cette simplicité rend parfois trčs problématique l'implantation de certaines applications. Postgres propose des fonctionnalités additionnelles puissantes en incorporant les quatres concepts de base qui suivent de telle maničre qu'il soit facile aux utilisateurs d'étendre le systčme :
D'autres fonctionnalités apportent plus de puissance et de souplesse :
Ces fonctionnalités rangent Postgres dans la catégorie des bases de données que l'on qualifie de relationnelles-objet. Veuillez noter que c'est une catégorie distincte de celle des bases orientées-objet qui, en général, ne sont pas autant adaptées ŕ la gestion des langages de bases de données relationnelles traditionnelles. Ainsi, męme si Postgres dispose de certaines fonctionnalités orientées-objet, elle est de plein pied dans le monde des bases de données relationnelles. En fait, certaines bases de données du commerce ont récemment incorporé certaines des fonctionnalités introduites par Postgres.
PostgreSQL est donc un SGBD relationnel-objet sophistiqué qui supporte quasiment toutes les constructions de SQL, y compris les transactions, les select imbriqués ainsi que les types et fonctions définis par l'utilisateur. C'est la base de données en open source la plus avancée qui soit.
Maintenant que nous savons quels outils et quelle architecture utiliser, il nous faut rassembler tous les morceaux.
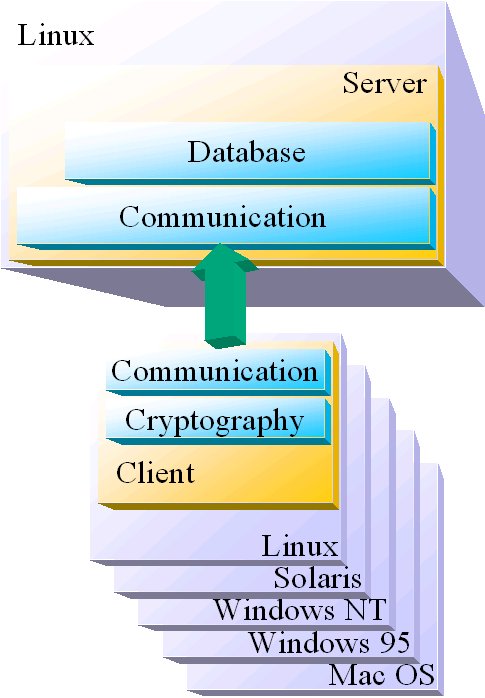
La plate-forme de développement choisie est Linux en vertu de ses bonnes caractéristiques dans le cadre d'une utilisation en systčme de développement. Le langage utilisé sera Java compte tenu de sa simplicité.
Côté serveur, un des points les plus importants ŕ définir, c'est le choix du serveur de base de données. Celle-ci est assez importante dans la mesure oů elle va contenir des données de premier ordre sur le concours, par exempl des informations détaillées sur les clients, l'ensemble des clés que chaque client est actuellement en train de traiter ou encore quelle est la derničre sortie.
La base de données sera développée en utilisant une base de données relationelle-objet libre du nom de PostgreSQL. Le logiciel serveur, totalement développé en Java, s'interfacera avec la base de données par le biais de l'API JDBC.
Configuration de l'architecture finale en client/serveur
Une des principales fonctions d'un serveur, c'est d'attendre la réception de requętes en provenance d'un client. Le serveur de clé DES présente le męme comportement. Le serveur démarre, attend et traite les requętes. Pour pouvoir communiquer avec les clients, il lui est nécessaire de posséder quelques fonctionnalités réseau. Dans ce cas, le serveur reçoit les requętes de ses clients via RMI. Ce dernier a été choisi en vertu de la couche d'abstraction qu'il offre entre le programme Java et les arcanes inhérentes au réseau.
Côté client, une des choses les plus importantes ŕ implanter, ce sont les fonctionnalités de cryptographie. Le logiciel client doit ętre en mesure de faire tourner l'algorithme DES. Dans la mesure oů le logiciel client connaît une partie du texte en clair et le message secret dans son entier, il doit ętre en mesure d'essayer de décrypter le message secret en utilisant une clé qui lui est fournie par le serveur et de comparer le résultat avec le texte en clair partiel.
Comme sur le serveur, le logiciel client est entičrement codé en Java. Cela permet ŕ un plus grand nombre d'ordinateurs et de plate-formes différents de se joindre rapidement au concours, permettant d'accroître considérablement la puissance de calcul dévolue pour trouver aussi vite que possible une solution au problčme posé : trouver la bonne clé DES.
Le DES 56-bit n'est plus sűr de nos jours. Il est clair qu'avec la puissance de calcul dont nous disposons ainsi qu'avec les possibilités accrues de mise en réseau dont nous pouvons tirer parti, comme Internet, il est aisé de mettre en place une architecture pour craquer une clé DES.
Linux et Java sont deux des outils qui permettent la création aisée de telles architectures et mettent ces possibilités ŕ la portée de presque tout le monde. Linux, parce que c'est un systčme d'exploitation libre, puissant, rapide et simple qui permet la mise en oeuvre de serveurs puissants. Java, parce qu'il est facile ŕ apprendre et indépendant de l'architecture ce qui permet un développement rapide sur un grand nombre de plate-formes différentes.
[1] RSA Laboratories - Cryptographic Research and Consultation, "Answers to Frequently Asked Questions About Today's Cryptography - Version 3.0", RSA Data Security, 1996
[2] Schneier, Bruce, "Applied Cryptography - Protocols, Algorithms and Source code in C", John Wiley & sons, Inc., 1996
[3] "DES Challenge II", RSA Laboratories, RSA Data Security, http://www.rsa.com/rsalabs/des2, 1997
Copyright © 1999, Carlos Serrao - Adaptation française de Pierre Tane (NdT: un grand merci ŕ Joel Sagnes pour son attentive relecture :-) )
"Linux Gazette...making Linux just a little more fun!"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}