| Linux Gazette n°55 | ||
|---|---|---|
| Précédent | Suivant | |
Le bloc logique est la plus petite unité d'allocation visible d'un systčme de fichiers ŕ travers les appels systčmes. Cela signifie que le stockage d'un fichier dont la taille en octets est inférieure ŕ la taille d'un bloc logique occupera sur disque la taille du bloc logique.
De męme, si la taille d'un fichier n'est pas divisible de façon entičre par la taille du bloc logique (ie. taille_fichier modulo taille_bloc != 0), le systčme de fichiers allouera un nouveau bloc qui ne sera pas rempli entičrement, gaspillant ainsi de l'espace disque. Ce gaspillage d'espace disque est ce que l'on appelle la fragmentation interne. Remarquons que plus la taille du bloc logique est importante, plus importante sera la fragmentation interne.
La fragmentation externe d'un fichier est le fait d'avoir les blocs constituant le fichier répartis de façon non contiguë sur tout le disque, réduisant ainsi les performances d'accčs ŕ ce fichier, du fait de l'augmentation des mouvements des tętes de lecture du disque nécessaire ŕ l'accčs ŕ ce fichier.
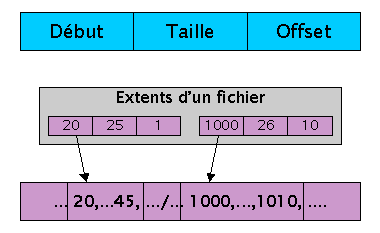
Les extents sont des ensembles de blocs logiques contigus, utilisés dans divers systčmes de fichiers voire męme dans certains SGBD. Le descripteur d'un extent ressemble ŕ début, taille, offset, oů début est l'adresse du premier bloc de l'extent, taille est la taille en nombre de blocs, offset est l'offset dans le fichier oů se situe l'extent.
Extent
L'utilisation des extents améliore l'utilisation de l'espace, puisque tous les blocs d'un extent sont contigus. Cette amélioration amčnera de meilleures performances en lecture séquentielle, car moins de mouvements de tęte de lecture seront nécessaires. Remarquons ainsi que l'utilisation des extents réduit le problčme de la fragmentation externe, puisque les blocs sont rassemblés. Mais l'utilisation d'extent n'est pas toujours la panacée. Par exemple, si nos applications demandent des extents d'une taille proche de celle des blocs logiques, tous les bénéfices seront perdus, puisque ces extents ressembleront ŕ autant de blocs logiques.
Pour clore le chapitre amélioration des performances, l'utilisation d'extents améliore aussi les transferts simultanés de plusieurs blocs et améliore les taux de réussite des mémoires tampons des disques durs.
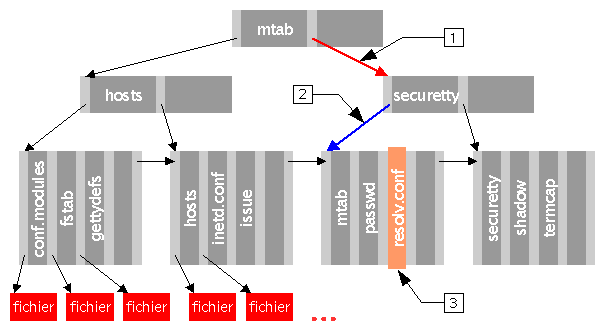
Arbre B+[2] : les clés des noeuds sont ordonnées dans l'arbre, ce qui améliore les temps de recherche, recherche qui n'est plus séquentielle. Les feuilles sont chaînées entre elles.
Pour localiser le fichier resolv.conf, nous commençons ŕ la racine de l'arbre, lisons séquentiellement, et trouvons qu'il n'y a pas de clé supérieure ŕ celle de resolv.conf, donc nous suivons le dernier pointeur (en rouge).
Nous sommes redirigés sur un autre noeud de l'arbre. On fait de męme qu'avant, on lit les clés jusqu'ŕ "securetty", qui est supérieure ŕ "resolv.conf". On suit donc le lien associé (en bleu).
Nous arrivons ainsi ŕ une feuille de l'arbre. Il est temps de lire séquentiellement par ordre ascendant les clés présentes. Nous trouvons enfin la clé désirée, nous permettant d'utiliser le pointeur associé vers les données du fichier "resolv.conf"
La structure de données de type arbre B+ est depuis longtemps utilisée pour l'indexation de bases de données.
Cette structure apporte aux SGBD une maničre rapide et stable dans les performances pour accéder ŕ leurs enregistrements. Le terme arbre B+ vient de «arbre balancé», équilibré en français. Le signe «+» signifie que la structure arbre B+ est une version modifiée de l'arbre B. [3] original, modification qui consiste en le maintien de pointeurs entre les différentes feuilles de l'arbre, ce afin de ne pas pénaliser les accčs séquentiels de feuille en feuille. Puisque les arbres B et B+ sont issus des bases de données, nous utiliserons des analogies avec celles-ci pour les expliquer.
Les arbres B+ sont constitués de deux types d'éléments : les noeuds et les feuilles. Les deux sont une paire (clé, pointeur), ordonnées de façon ascendante par les valeurs de clés, avec un pointeur final qui n'a pas de clé correspondante. Alors que les pointeurs des noeuds pointent sur d'autres noeuds ou feuilles, les pointeurs des feuilles pointent directement sur l'information utilisable. Chaque paire (clé, pointeur) organise l'information au sein de l'arbre B. En base de données, chaque enregistrement possčde un champ-clé, un champ qui sert ŕ distinguer un enregistrement particulier des tous les autres enregistrements de męme type. Les B-arbres utilisent ces champs-clés pour indexer les enregistrements d'une base de données pour améliorer les temps d'accčs ŕ l'information.
Ainsi que nous l'avons vu, un noeud (clé, pointeur) est utilisé pour pointer sur un autre noeud ou sur une feuille. Dans les deux cas, la clé associée au pointeur aura une valeur supérieure ŕ toutes les valeurs de clés stockées dans les noeuds cibles. De plus, les enregistrements ayant des valeurs de clés identiques devront ętre adressés par la paire suivante dans le noeud. Ce point est la principale raison de l'existence du pointeur de fin qui n'a aucune valeur de clé correspondante. Notons qu'ŕ partir du moment oů une clé est utilisée dans une paire, il doit exister un autre pointeur pour atteindre les enregistrements ayant cette męme valeur de clé. Ce pointeur de fin est utilisé dans les feuilles pour pointer sur la feuille suivante. On peut ainsi passer les contenus en revue aussi de façon séquentielle.
Les arbres B+ doivent ętre équilibrés. Cela signifie que la longueur du chemin nous menant de la racine de l'arbre ŕ chacune des feuilles doit toujours ętre la męme. En plus, les feuilles doivent contenir un nombre minimal de paires pour exister. Quand le contenu d'une feuille tombe sous le seuil, les paires seront intégrées ŕ une autre feuille.
Pour rechercher un enregistrement particulier, nous procéderons ainsi :
Supposons que nous recherchons un enregistrement ayant une clé K. Nous partons du noeud racine, et passons en revue séquentiellement les clés qu'il contient, jusqu'ŕ ce que nous trouvions une clé de valeur supérieure ŕ celle de K. Nous passons ensuite au noeud (ou feuille, nous ne savons pas encore) pointé par le pointeur associé ŕ la clé. A ce stade, nous répétons la męme opération si nous ne sommes pas arrivés ŕ une feuille. Arrivé sur une feuille, nous criblons séquentiellement les paires contenues jusqu'ŕ la valeur K. Moins de blocs sont nécessaires d'ętre lus pour arriver au bloc désiré, ce qui qualifie cette technique comme étant de moindre complexité qu'une recherche purement séquentielle, oů dans le plus mauvais cas, nous devons lire tous les enregistrements pour trouver celui que nous recherchons.
C'est le nom du systčme de fichiers utilisé au début par SCO, System V[4], et d'autres Unix. Le noyau Linux inclut le support optionnel d'UFS. La plupart des Unix continuent ŕ utiliser UFS, avec néanmoins quelques améliorations mineures.
VFS est la couche logicielle du noyau[5] qui fournit une interface de programmation applicative [API en anglais] unifiée pour accéder aux services des systčmes de fichiers, quel que soit le systčme de fichier particulier utilisé derričre. Tous les pilotes de systčmes de fichiers (VFAT, Ext2FS, JFS) doivent ainsi fournir un certain nombre de routines ŕ la couche VFS pour ętre utilisables sous Linux. VFS est la couche qui permet aux applications de comprendre et d'utiliser tant de systčmes de fichiers différents, męme les systčmes de fichiers commerciaux.
| [1] | NdT : le terme anglais extent ne trouvant sa traduction que dans une périphrase longue (ŕ savoir : unité d'allocation d'espace de taille variable), le terme anglais sera conservé tel quel. |
| [2] | NDE : Dans le schéma, les clés sont les noms de fichiers. La ligne au dessus des cases rouges contient une clé pour chaque fichier du répertoire : ce sont les feuilles. Au dessus se situent les noeuds, les clés étant choisies par le systčme pour optimiser l'accčs aux données. |
| [3] | NdT : on trouve aussi B-Arbre, dans la littérature en français de géométrie algorithmique |
| [4] | NdT : UFS est en fait d'origine BSD, ce qui nous le fait retrouver sur SunOS4 (et donc Solaris), Ultrix (et donc OSF/1 - Digital Unix - Tru64), et d'autres encore. Le systčme de fichiers des Unix System V est HFS, Hierarchical File System, que l'on retrouve par exemple sur HP-UX |
| [5] | NdT : noyau Linux, mais le lecteur trouvera aussi ce genre de chose sur d'autres Unix |
| Précédent | Sommaire | Suivant |
| Linux Gazette n°55 | Le journal de transactions |