| Linux Gazette nį55 | ||
|---|---|---|
| Prťcťdent | Suivant | |
UFS et Ext2FS furent conÁus alors que les capacitťs des disques durs et autres media de stockage ťtaient de taille moins importante que maintenant. La croissance rapide des media de stockage induirent des tailles de fichiers, de rťpertoires, et de partitions plus importantes, causant ainsi de plus en plus de problŤmes aux systŤmes de fichiers. Ces problŤmes dťcoulent des structures internes sous-tendant les systŤmes de fichiers. Enfin, ces structures ťtaient adťquates pour les tailles moyennes observťes des fichiers et rťpertoires, mais se sont avťrťes inefficaces pour les besoins actuels.
Il existe deux problŤmes majeurs avec les anciennes structures :
Elles sont incapables de gťrer les nouvelles capacitťs de stockage†: ainsi que nous l'avons dit, les anciens systŤmes de fichiers ťtaient conÁus pour certains paramŤtres de taille de fichiers, rťpertoires et partitions. Les structures des systŤmes de fichiers ont un nombre fixť de bits pour stocker la taille d'un fichier, pour stocker l'adresse d'un bloc, etc... En consťquence de quoi, les tailles de fichier, de rťpertoire, et de partition et le nombre de fichiers dans un rťpertoire sont eux aussi limitťs. Il manque ainsi aux anciennes structures la capacitť de gťrer les tailles de certains objets.
Elles sont peu adaptťesz ŗ la gestion des nouvelles capacitťs de stockage : bien qu'elles puissent parfois gťrer certaines tailles d'objets, elles sont parfois incapables de les gťrer pour des raisons de performance. La principale raison ťtant que certaines structures se comportent correctement avec les anciennes volumťtries, mais induisent des pertes parfois sťvŤres de performances avec les nouvelles.
Les systŤmes de fichiers de nouvelle gťnťration ont ťtť conÁus pour pallier ces problŤmes, gardant ŗ l'esprit le problŤme de l'ťvolutivitť. Un certain nombre de nouvelles structures de donnťes et d'algorithmes ont ainsi ťtť intťgrťs ŗ ces nouveaux systŤmes de fichiers. Nous allons maintenant expliquer plus avant les problŤmes dťcrits plus haut et les techniques employťes pour les surmonter.
La plupart des nouveaux systŤmes de fichiers ont vu la taille de certains de leurs champs internes s'ťtendre, afin de passer outre les limitations des systŤmes actuels. Les nouvelles limites pour ces systŤmes sont†:
Tableau 1. Limites des systŤmes de fichiers
| Taille maximale du systŤme de fichiers | Taille de blocs | Taille maximale de fichier | |
| XFS | 18 000 peta-octets (Po) | 512 octets ŗ 64 Ko | 9 000 Po |
| JFS | Blocs de 512 octets : 4 Po | 512, 1024, 2048 et 4096 octets | Blocs de 512 octets : 512 To |
| Blocs de 4 Ko : 32 Po | Blocs de 4 Ko : 4 Po | ||
| ReiserFS | 4 milliards de blocs, soit 16 tera-octets | 64 Ko maximum, fixť actuellement ŗ 4 Ko | 4 Go en v3.5 |
| 2^10 Po en v3.6 | |||
| Ext3FS | 4 To | De 1 ŗ 4 Ko | 2 Go |
Actuellement, la taille maximale d'un pťriphťrique en mode bloc limite la taille d'un systŤme de fichiers ŗ 2 To, la couche VFS induisant une autre limite : la taille d'un fichier infťrieure ŗ 2 Go. La bonne nouvelle est que nous avons maintenant des systŤmes de fichiers capable d'ťvoluer en capacitť, et qu'ŗ la sortie du noyau 2.4, je suis sŻr que ces limites seront ťtendues. Notons que XFS et JFS sont des portages de systŤmes de fichiers commerciaux ; ils furent dťveloppťs pour d'autres systŤmes d'exploitation oý ces limites n'existaient pas.
La plupart des systŤmes de fichiers maintiennent des structures ont sont suivis les blocs libres. Ces structures sont souvent des listes chaÓnťes, contenant les adresses de tous les blocs libres. Ainsi, le systŤme de fichiers est capable de satisfaire les besoins d'allocation de stockage des applications. UFS et Ext2FS utilisent ce que l'on appelle une bitmap[1] pour le suivi de ces blocs libres. Cette carte est un est un tableau de bits, oý chaque bit est associť ŗ un bloc dans le systŤme de fichier de la partition. L'ťtat de l'allocation de chaque bloc est reflťtť dans la carte, oý un ę1Ľ reprťsente un bloc logique allouť, et un ę0Ľ un bloc non-allouť, libre. Le principal problŤme avec ce genre de structure est que plus la taille d'un systŤme de fichiers augmente, plus la taille de la carte augmente, puisque chaque bloc doit avoir son bit correspondant dans la carte. Et tant que nous utiliserons un algorithme de recherche sťquentielle des blocs libres, nous constaterons une perte de performance puisque le temps de recherche augmentera de faÁon linťaire (complexitť en O(n), oý n est la taille de la carte). Notons que l'approche carte n'est pas si mauvaise quand la taille du systŤme de fichiers est raisonnable, mais plus la taille augmentera, moins bien la structure se comportera.
La solution fournie par les systŤmes de fichiers de nouvelle gťnťration est l'utilisation d'extents conjuguťe ŗ une organisation en arbre B+. L'approche extent est intťressante car elle permet de localiser plusieurs blocs disponibles en mÍme temps. De plus, ils permettent aussi de rťduire la taille de la structure de gestion, puisque plusieurs blocs sont gťrťs avec moins d'information. Par consťquent, un bit pour chaque bloc n'est plus nťcessaire. En outre, avec l'utilisation des extents, la taille de la structure de gestions des blocs libre ne dťpend plus de la taille du systŤme de fichiers (la taille de structure dťpend du nombre d'extents gťrťs). Nťanmoins, si le systŤme de fichiers est si fragmentť qu'il existe un extent pour chaque bloc libre, la structure de gestion serait plus grande que pour l'approche ŗ† bitmap. Notez que les performances devraient Ítre sensiblement augmentťes si notre structure gťrait uniquement les blocs libres, puisque moins d'ťlťments auraient ŗ Ítre visitťs. En outre, avec l'utilisation d'extents, mÍme s'ils sont gťrťs en liste et que des algorithmes sťquentiels de balayage soient utilisťs, les performances en seraient quand mÍme amťliorťes puisque la structure englobe plusieurs blocs dans un extent, rťduisant ainsi le temps de localisation d'un certain nombre de blocs libres.
La seconde approche pour surmonter le problŤme de gestion des blocs libres est l'utilisation de structures complexes qui amŤnent ŗ l'utilisation d'algorithmes de balayage de moindre -complexitť. Nous tous savons qu'il y a de meilleures voies d'organiser un ensemble d'ťlťments devant Ítre localisťs que l'utilisation des listes chaÓnťes avec des algorithmes de balayage sťquentiels. Les arbres B+ sont utilisťs puisqu'ils peuvent localiser des objets rapidement. Ainsi, les blocs libres sont organisťs en arbres B+ au lieu de listes, afin de tirer profit des algorithmes de recherche rapide. Quand plusieurs blocs libres sont demandťs par les applications, le systŤme de fichiers traverse ęl'arbre de gestion des blocs libresĽ, afin de localiser l'espace libre demandť. Il existe en outre l'approche ęArbre B+ d'extentsĽ, oý des extents et non des blocs sont organisťs dans l'arbre. Cette approche rend diffťrentes techniques d'indexation possibles. L'indexation par taille d'extent, mais ťgalement par la position des extents, sont des techniques mises en application qui rendent le systŤme de fichiers capable de localiser rapidement plusieurs blocs libres, que ce soit par leur taille ou par leur emplacement.
Tous les systŤmes de fichiers utilisent un objet spťcial appelť rťpertoire. Les rťpertoires, vus du systŤme de fichiers, est un ensemble d'entrťes de rťpertoire. Ces entrťes sont des paires (numťro d'inode, nom de fichier), oý le ęnumťro d'inodeĽ est le numťro d'inode (structure interne du systŤme de fichiers) utilisť pour gťrer les informations relatives aux fichiers. Quand une application veut rechercher un certain fichier dans un rťpertoire, par son nom de fichier, la ęstructure d'entrťes de rťpertoireĽ doit Ítre balayťe. Les anciens systŤmes de fichiers ont organisť les entrťes de rťpertoire par des listes chaÓnťes, utilisant alors des algorithmes de recherche sťquentiels. Par consťquent, avec des rťpertoires de grande taille, rťfťrenÁant des milliers de fichiers et d'autres rťpertoires, les performances se rťduisent d'autant. Ce problŤme, comme celui dťcrit pour les blocs d'espace libre, est ťtroitement liť ŗ† la structure utilisťe. Les systŤmes de fichiers de nouvelle gťnťration ont ainsi besoin de structures de donnťes et d'algorithmes plus performants pour localiser rapidement un fichier dans un rťpertoire.
Solution employťe : les systŤmes de fichiers passťs en revue ici utilisent les arbres B+ pour organiser les entrťes de rťpertoire, ce qui amťliore les temps de recherche. Dans ces systŤmes de fichiers, les entrťes de chaque rťpertoire sont indexťes par le nom de fichier.
Ainsi, quand un fichier d'un rťpertoire donnť est demandť, l'arbre B+ de ce rťpertoire est traversť pour localiser rapidement l'inode correspondant. L'utilisation des arbres B+ est liťe ŗ chaque systŤme de fichiers. Il existe en effet des systŤmes de fichiers qui gŤrent un arbre par rťpertoire, alors que d'autres gŤrent un arbre par arborescence de fichiers.
Quelques anciens systŤmes de fichiers ont ťtť conÁus avec une certaine idťe des conditions d'utilisation. Ext2fs et UFS ont ťtť conÁus en partant du principe que les systŤmes de fichiers contiendraient essentiellement de petits fichiers. C'est ce qui expliquent ce ŗ quoi ressemblent les inodes de Ext2FS ou UFS. Pour ceux qui ne connaissent pas encore la notion d'inode, nous allons l'expliquer briŤvement.
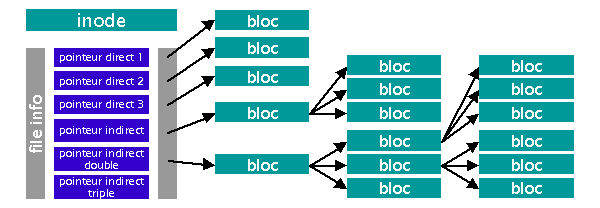
Un inode est la structure employťe par UFS et Ext2FS pour gťrer les informations relatives aux fichiers. Sont gťrťs dans l'inode les permissions sur le fichier, son type, le nombre de liens[2], et les pointeurs sur les blocs du systŤme de fichiers.
Un inode peut contenir des pointeurs directs qui sont les adresses logiques des blocs logiques du systŤme de fichiers utilisťs pour stocker le contenu du fichier, mais il peut aussi contenir des pointeurs indirects simples, voire doubles ou mÍme triples. Les pointeurs indirects contiennent l'adresse de blocs logiques oý sont d'autres pointeurs qui eux donnent l'adresses des blocs du fichier. Les indirections doubles pointent sur des blocs contenant des indirections simples. De mÍme, les indirections triples pointent sur des indirections doubles. Le problŤme avec cette technique d'adressage est que si la taille du fichier croit, indirections simples, doubles et mÍme triples sont utilisťes.
Notons que l'utilisation de pointeurs indirects mŤne ŗ l'augmentation du nombre d'accŤs disques, car un plus grand nombre de blocs doit Ítre lu pour trouver le bloc demandť. Cela mŤne ŗ une augmentation du temps de recherche en corrťlation avec l'augmentation de la taille des fichiers. Vous pourriez vous demander pourquoi les crťateurs d'Ext2FS n'ont pas uniquement utilisť les pointeurs indirects simples, dťmontrťs plus rapides ?
La principale raison en est que les inodes ont une taille fixe, et que l'utilisation de pointeurs simples uniquement amŤnerait ŗ utiliser des inodes de plus grande taille, pour stocker tous les pointeurs directs utilisables, ce qui gaspillerait inutilement de l'espace disque lorsque l'on stocke de petits fichiers.
Inode (Ext2FS) : les fichiers de plus grande taille nťcessitent plus d'accŤs disque, car utilisant des indirections simples, voire doubles et mÍme triples pour accťder aux donnťes.
Solution employťe : les nouveaux systŤmes de fichiers doivent alors continuer ŗ utiliser l'espace efficacement, et fournissent de meilleures techniques d'adressage pour des fichiers de plus grande taille. La principale diffťrence avec les anciens systŤmes de fichiers est, une fois de plus, l'utilisation d'arbres B+. Les systŤmes de fichiers que nous ťtudions utilisent les arbres B+ pour gťrer les blocs des fichiers. Les blocs sont classťs par leur adresse (offset) dans le fichier; puis, quand une certaine adresse dans le fichier est demandťe les sous-routines du systŤme de fichiers parcourent l'arbre des blocs pour localiser le bloc requis. Ces techniques employťes sont aussi propres ŗ chaque systŤme de fichier.
Afin de rťduire au minimum l'utilisation des pointeurs indirects, nous pourrions penser ŗ utiliser de plus grands blocs logiques. Ceci mŤnerait ŗ un ratio d'information sur nombre de pointeurs plus ťlevť, ayant pour rťsultat une utilisation moindre des indirections. Mais, ces blocs logiques plus grands augmentant la fragmentation interne, d'autres techniques sont utilisťes. L'utilisation des extents rassemblant un ensemble de plusieurs blocs logiques est une de ces techniques.
L'utilisation des extents en lieu et place des pointeurs sur blocs causerait le mÍme effet que l'augmentation de la taille des blocs, puisque le taux information sur nombre de pointeurs augmente. Certains des systŤmes de fichiers passťs en revue utilisent des extents pour surmonter le problŤme de l'adressage dans les fichiers de grande taille.
D'ailleurs, des extents peuvent Ítre indexťs dans un arbre B+ par leur adresse ŗ l'intťrieur du fichier, amťliorant ainsi les temps de lecture. Les nouveaux inodes maintiennent ainsi, jusqu'ŗ un certain point, quelques pointeurs directs sur les extents, et, dans le cas oý le fichier aurait besoin de plus d'extents, ceux-ci seront organisťs dans un arbre B+. Pour maintenir un bon niveau de performance lors de l'accŤs aux fichiers de petite taille, les systŤmes de fichiers de nouvelle gťnťration stockent les donnťes directement dans l'inode. Ainsi, chaque accŤs ŗ l'inode permettra un accŤs immťdiat aux donnťes. Cette technique est particuliŤrement utile pour les liens symboliques oý l'information stockťe est infime.
Tableau 2. Capacitťs et particularitťs des systŤmes de fichiers ťtudiťs
| Techniques / SystŤme de fichiers | Gestion des blocs libres | Utilisation d'extents pour l'espace libre | B-arbres pour les entrťes de rťpertoire | B-arbres pour adresser les blocs des fichiers | Extents pour adresser les blocs des fichiers | Donnťes de petits fichier dans l'inode) | Lien symbolique dans l'inode | Entrťes de (petits) rťpertoires dans l'inode |
| XFS | Arbres B+, indexťs par leur offset et leur taille | OUI | OUI | OUI | OUI | OUI | OUI | OUI |
| JFS | Arbre & Binary Buddy[a] | NON | OUI | OUI | OUI | NON | OUI | 8 au maximum |
| ReiserFS[b] | Bitmap based | Non supportť pour l'instant | Sous-arbre de l'arbre du SF | Dans l'arbre du SF | A venir dans la version 4 | [c] | [c] | [c] |
| Ext3FS | Ext3FS n'a pas ťtť conÁu ŗ partir de rien ; c'est une surcouche de Ext2FS, et par le fait ne supporte pas les diverses techniques citťes ci-dessus. Il apporte en fait la journalisation ŗ Ext2FS, tout en prťservant une compatibilitť ascendante. | |||||||
| Remarques : a. Binary Buddy : JFS emploie une approche diffťrente pour organiser les blocs libres. La structure est un arbre, oý les feuilles sont des bitmaps au lieu d'extents. En fait, les feuilles sont la reprťsentation de la technique d'allocation dite du Binary Buddy (la technique du binary buddy est utilisťe pour suivre et rassembler les blocs contigus les groupes de blocs d'espace libre, pour en faire des groupes de grande taille - NdT : voir ŗ ce sujet http://www.osinet.fr/code/glo.asp?Initial=B#binary-buddies). Comme pour la technique de la bitmap, chaque bit correspond ŗ un bloc sur disque. Une valeur ŗ 1de ce bit indique que le bloc est allouť, une valeur ŗ 0 qu'il est libre. Ces bouts de bitmap, contenant chacun 32 bits, peuvent Ítre reprťsentťs par un nombre hexadťcimal. Ainsi, une valeur ŗ ęFFFFFFFFĽ signifie que tous les blocs correspondants sont tous allouťs. Enfin, en utilisant cette valeur d'allocation ainsi que d'autres informations, JFS construit un arbre un groupe de blocs contigus peuvent Ítre rapidement localisťs. b. Le coeur de ce systŤme de fichiers est l'arbre B* (une version amťliorťe de l'arbre B+). La principale diffťrence en est que chaque objet est placť dans un seul et unique arbre. Cela signifie qu'il n'y a pas un arbre par rťpertoire, mais chaque rťpertoire a son sous-arbre de l'arbre principal du systŤme de fichiers. Cet usage implique ŗ ReiserFS d'utiliser des techniques d'indexation plus complexes. Une autre diffťrence importante est que ReiserFS n'utilise pas les extents, bien que leur utilisation soit prťvue ŗ l'avenir. c. ReiserFS organise tous les objets du systŤme de fichiers dans un arbre B*. Ces objets, rťpertoires, blocs de fichiers, attributs de fichiers, liens, et autres sont tous organisťs dans le mÍme arbre. Des techniques de hachage pour obtenir le champ clť qui permettra d'organiser les ťlťments de l'arbre. Le plus de cette technique est qu'en changeant de mťthode de hachage, on change la faÁon dont le systŤme de fichiers organise les ťlťments, et donc leur position relative dans l'arbre. Il y existe des mťthodes de hachage qui aident ŗ maintenir la localisation spatiale des ťlťments entre eux (les attributs avec les entrťes de rťpertoire, les attributs avec les donnťes des fichiers, etc...) | ||||||||
| [1] | NdT†: carte de bits, mais nous conserverons le terme original |
| [2] | NdT : liens matťriels, hard-links |
| Prťcťdent | Sommaire | Suivant |
| Le journal de transactions | Autres amťliorations |